


Новости

18.05.2021
Книга «Роман с Data Science. Как монетизировать большие данные»
В послужном списке Романа — создание с нуля собственной компании с офисами в Европе и Южной Америке, ставшей лидером по применению искусственного интеллекта (AI) на российском рынке. Кроме того, автор книги создал с нуля аналитику в Ozon.ru. Эта книга предназначена для думающих читателей, которые хотят попробовать свои силы в области анализа данных и создавать сервисы на их основе. Она будет вам полезна, если вы менеджер, который хочет ставить задачи аналитике и управлять ею. Если вы инвестор, с ней вам будет легче понять потенциал стартапа. Те, кто «пилит» свой стартап, найдут здесь рекомендации, как выбрать подходящие технологии и набрать команду. А начинающим специалистам книга поможет расширить кругозор и начать применять практики, о которых они раньше не задумывались, и это выделит их среди профессионалов такой непростой и изменчивой области.
Нужно ли уметь программировать?
Да, нужно. В XXI веке понимать, как использовать программирование в своей работе, желательно каждому человеку. Раньше программирование было доступно только узкому кругу инженеров. Со временем прикладное программирование стало все более доступным, демократичным и удобным.
Я научился программировать самостоятельно в детстве. Отец купил компьютер «Партнер 01.01» в конце 80-х, когда мне было примерно одиннадцать лет, и я начал погружаться в программирование. Вначале освоил язык BASIC, потом уже добрался до ассемблера. Изучал все по книгам — спросить тогда было не у кого. Задел, который был сделан в детстве, мне очень пригодился в жизни. В то время моим главным инструментом был белый мигающий курсор на черном экране, программы приходилось записывать на магнитофон — все это не идет ни в какое сравнение с теми возможностями, которые есть сейчас. Азам программирования научиться не так сложно. Когда моей дочери было пять с половиной лет, я посадил ее за несложный курс по программированию на языке Scratch. С моими небольшими подсказками она прошла этот курс и даже получила сертификат MIT начального уровня.
Прикладное программирование — это то, что позволяет автоматизировать часть функций сотрудника. Первые кандидаты на автоматизацию — повторяющиеся действия.
В аналитике есть два пути. Первый — пользоваться готовыми инструментами (Excel, Tableau, SAS, SPSS и т. д.), где все действия совершаются мышкой, а максимум программирования — написать формулу. Второй — писать на Python, R или SQL. Это два фундаментально разных подхода, но хороший специалист должен владеть обоими. При работе с любой задачей нужно искать баланс между скоростью и качеством. Особенно это актуально для поиска инсайтов. Я встречал и ярых приверженцев программирования, и упрямцев, которые могли пользоваться только мышкой и от силы одной программой. Хороший специалист для каждой задачи подберет свой инструмент. В каком-то случае он напишет программу, в другом сделает все в Excel. А в третьем — совместит оба подхода: на SQL выгрузит данные, обработает датасет в Python, а анализ сделает в сводной (pivot) таблице Excel или Google Docs. Скорость работы такого продвинутого специалиста может быть на порядок больше, чем одностаночника. Знания дают свободу.
Еще будучи студентом, я владел несколькими языками программирования и даже успел поработать полтора года разработчиком ПО. Времена тогда были сложными — я поступил в МФТИ в июне 1998 года, а в августе случился дефолт. Жить на стипендию было невозможно, денег у родителей я брать не хотел. На втором курсе мне повезло, меня взяли разработчиком в одну из компаний при МФТИ — там я углубил знание ассемблера и Си. Через какое-то время я устроился в техническую поддержку компании StatSoft Russia — здесь я прокачал статистический анализ. В Ozon.ru прошел обучение и получил сертификат SAS, а еще очень много писал на SQL. Опыт программирования мне здорово помог — я не боялся чего-то нового, просто брал и делал. Если бы у меня не было такого опыта программирования, в моей жизни не было бы многих интересных вещей, в том числе компании Retail Rocket, которую мы основали с моими партнерами.
Датасет
Датасет — это набор данных, чаще всего в виде таблицы, который был выгружен из хранилища (например, через SQL) или получен иным способом. Таблица состоит из столбцов и строк, обычно именуемых как записи. В машинном обучении сами столбцы бывают независимыми переменными (independent variables), или предикторами (predictors), или чаще фичами (features), и зависимыми переменными (dependent variables, outcome). Такое разделение вы встретите в литературе. Задачей машинного обучения является обучение модели, которая, используя независимые переменные (фичи), сможет правильно предсказать значение зависимой переменной (как правило, в датасете она одна).
Основные два вида переменных — категориальные и количественные. Категориальная (categorical) переменная содержит текст или цифровое кодирование «категории». В свою очередь, она может быть:
- Бинарной (binary) — может принимать только два значения (примеры: да/нет, 0/1).
- Номинальной (nominal) — может принимать больше двух значений (пример: да/нет/не знаю).
- Порядковой (ordinal) — когда порядок имеет значение (пример, ранг спортсмена, номер строки в поисковой выдаче).
Количественная (quantitative) переменная может быть:
- Дискретной (discrete) — значение подсчитано счетом, например, число человек в комнате.
- Непрерывной (continuous) — любое значение из интервала, например, вес коробки, цена товара.
Рассмотрим пример. Есть таблица с ценами на квартиры (зависимая переменная), одна строка (запись) на квартиру, у каждой квартиры есть набор атрибутов (независимы) со следующими столбцами:
- Цена квартиры — непрерывная, зависимая.
- Площадь квартиры — непрерывная.
- Число комнат — дискретная (1, 2, 3, ...).
- Санузел совмещен (да/нет) — бинарная.
- Номер этажа — порядковая или номинальная (зависит от задачи).
- Расстояние до центра — непрерывная.
Описательная статистика
Самое первое действие после выгрузки данных из хранилища — сделать разведочный анализ (exploratory data analysis), куда входит описательная статистика (descriptive statistics) и визуализация данных, возможно, очистка данных через удаление выбросов (outliers).
В описательную статистику обычно входят различные статистики по каждой из переменных во входном датасете:
- Количество непустых значений (non missing values).
- Количество уникальных значений.
- Минимум/максимум.
- Среднее значение.
- Медиана.
- Стандартное отклонение.
- Перцентили (percentiles) — 25 %, 50 % (медиана), 75 %, 95 %.
Не для всех типов переменных их можно посчитать — например, среднее значение можно рассчитать только для количественных переменных. В статистических пакетах и библиотеках статистического анализа уже есть готовые функции, которые считают описательные статистики. Например, в библиотеке pandas для Python есть функция describe, которая сразу выведет несколько статистик для одной или всех переменных датасета:
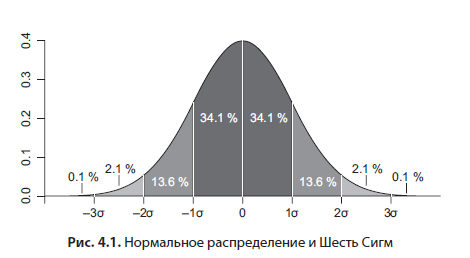
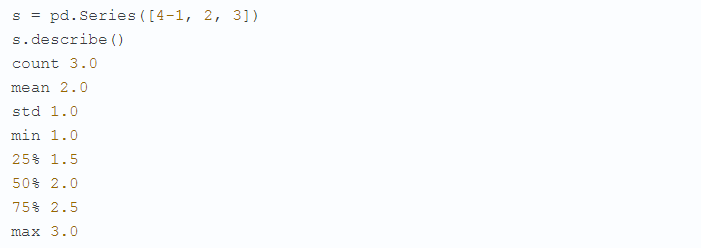 Хотя эта книга не является учебником по статистике, дам вам несколько полезных советов. Часто в теории подразумевается, что мы работаем с нормально распределенными данными, гистограмма которых выглядит как колокол (рис. 4.1).
Хотя эта книга не является учебником по статистике, дам вам несколько полезных советов. Часто в теории подразумевается, что мы работаем с нормально распределенными данными, гистограмма которых выглядит как колокол (рис. 4.1).
Очень рекомендую проверять это предположение хотя бы на глаз. Медиана — значение, которое делит выборку пополам. Например, если 25-й и 75-й перцентиль находятся на разном расстоянии от медианы, это уже говорит о смещенном распределении. Еще один фактор — сильное различие между средним и медианой; в нормальном распределении они практически совпадают. Вы будете часто иметь дело с экспоненциальным распределением, если анализируете поведение клиентов, — например, в Ozon.ru время между последовательными заказами клиента будет иметь экспоненциальное распределение. Среднее и медиана для него отличаются в разы. Поэтому правильная цифра — медиана, значение, которое делит выборку пополам. В примере с Ozon.ru это время, в течение которого 50 % пользователей делают следующий заказ после первого. Медиана также более устойчива к выбросам в данных. Если же вы хотите работать со средними, например, из-за ограничений статистического пакета, да и технически среднее считается быстрее, чем медиана, то в случае экспоненциального распределения можно его обработать натуральным логарифмом. Чтобы вернуться в исходную шкалу данных, нужно полученное среднее обработать обычной экспонентой.
Перцентиль — значение, которое заданная случайная величина не превышает с фиксированной вероятностью. Например, фраза «25-й перцентиль цены товаров равен 150 рублям» означает, что 25 % товаров имеют цену меньше или равную 150 рублям, остальные 75 % товаров дороже 150 рублей.
Для нормального распределения, если известно среднее и стандартное отклонение, есть полезные теоретически выведенные закономерности — 95 % всех значений попадает в интервал на расстоянии двух стандартных отклонений от среднего в обе стороны, то есть ширина интервала составляет четыре сигмы. Возможно, вы слышали такой термин, как Шесть сигм (six sigma, рис. 4.1), — эта цифра характеризует производство без брака. Так вот, этот эмпирический закон следует из нормального распределения: в интервал шести стандартных отклонений вокруг среднего (по три в каждую сторону) укладывается 99.99966 % значений — идеальное качество. Перцентили очень полезны для поиска и удаления выбросов из данных. Например, при анализе экспериментальных данных вы можете принять то, что все данные вне 99-го перцентиля — выбросы, и удалять их.
Графики
Хороший график стоит тысячи слов. Основные виды графиков, которыми пользуюсь я:
- гистограммы;
- диаграмма рассеяния (scatter chart);
- график временного ряда (time series) с линией тренда;
- график «ящики с усами» (box plot, box and whiskers plot).
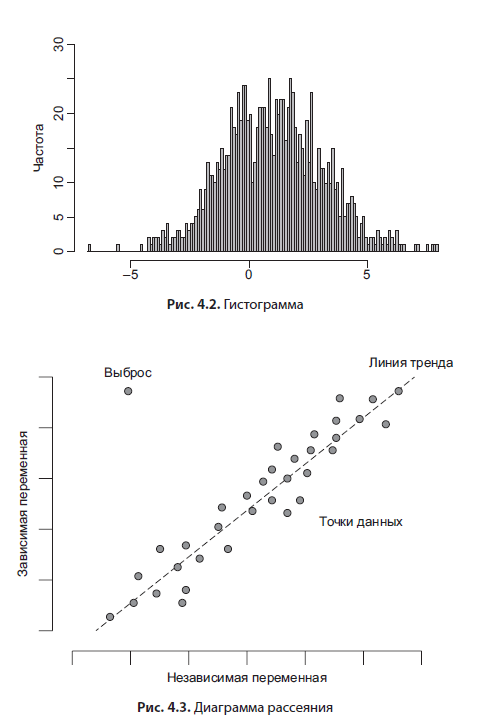
Гистограмма (рис. 4.2) — наиболее полезный инструмент анализа. Она позволяет визуализировать распределение по частотам появления какого-то значения (для категориальной переменной) или разбить непрерывную переменную на диапазоны (bins). Второе используется чаще, и если к такому графику дополнительно предоставить описательные статистики, то у вас будет полная картина, описывающая интересующую вас переменную. Гистограмма — это простой и интуитивно понятный инструмент.
График диаграммы рассеяния (scatterplot, рис. 4.3) позволяет увидеть зависимость двух переменных друг от друга. Строится он просто: на горизонтальной оси — шкала независимой переменной, на вертикальной оси — шкала зависимой. Значения (записи) отмечаются в виде точек. Также может добавляться линия тренда. В продвинутых статистических пакетах можно интерактивно пометить выбросы.
Графики временных рядов (time series, рис. 4.4) — это почти то же самое, что и диаграмма рассеяния, в которой независимая переменная (на горизонтальной оси) — это время. Обычно из временного ряда можно выделить две компоненты — циклическую и трендовую. Тренд можно построить, зная длину цикла, например, семидневный — это стандартный цикл продаж в продуктовых магазинах, на графике можно увидеть повторяющуюся картинку каждые 7 дней. Далее на график накладывается скользящее среднее с длиной окна, равной циклу, — и вы получаете линию тренда. Практически все статистические пакеты, Excel, Google Sheets умеют это делать. Если нужно получить циклическую компоненту, это делается вычитанием из временного ряда линии тренда. На основе таких простых вычислений строятся простейшие алгоритмы прогнозирования временных рядов.
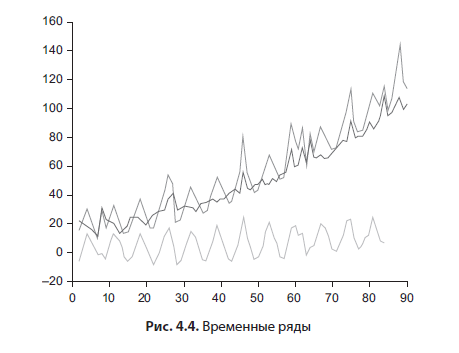
График «Ящик с усами» (box plot, рис. 4.5) очень интересен; в некоторой степени он дублирует гистограммы, так как тоже показывает оценку распределения.
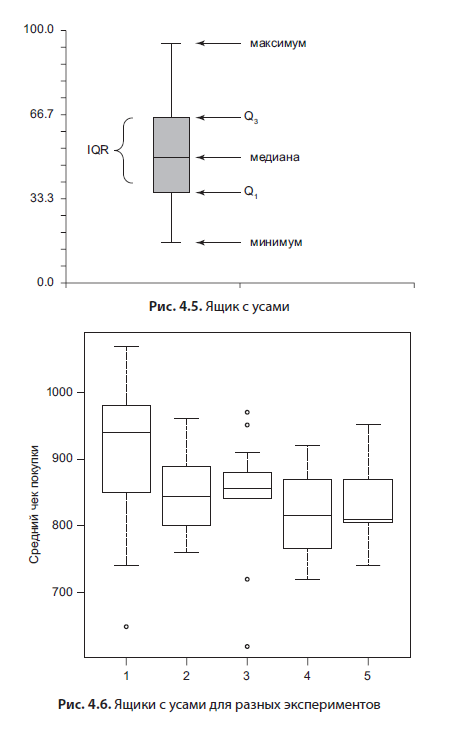
Он состоит из нескольких элементов: усов, которые обозначают минимум и максимум, ящика, верхний край которого 75-й перцентиль, нижний — 25-й перцентиль. В ящике линия — это медиана, значение «посередине», которая делит выборку пополам. Этот тип графика удобен для сравнения результатов экспериментов или переменных между собой. Пример такого графика ниже (рис. 4.6). Считаю это лучшим способом визуализации результатов тестирования гипотез.
С полным содержанием статьи можно ознакомиться на сайте "Хабрахабр":
Комментарии: 0
Пока нет комментариев