


Новости

24.11.2022
Книга «PyTorch. Освещая глубокое обучение»
Мы предполагаем, что читатели знакомы с основами императивного и объектно-ориентированного программирования. Поскольку в книге используется язык Python, вы должны быть знакомы с его синтаксисом и рабочей средой. Необходимое условие: уметь устанавливать пакеты и выполнять сценарии Python на вашей платформе. У читателей, работавших ранее на C++, Java, JavaScript, Ruby и других подобных языках программирования, не должно возникнуть проблем с этим, хотя может потребоваться изучить некоторые дополнительные материалы. Аналогично не помешает (а возможно, и необходимо) знакомство с библиотекой NumPy. Мы также ожидаем от вас понимания основ линейной алгебры, в частности знания, что такое матрицы, векторы и скалярное произведение.
Предобученные сети
В этой главе мы обсудим три часто встречающиеся предобученные модели: модель для маркировки изображения в соответствии с его содержимым, модель, способную формировать новое изображение на основе исходного, и модель, описывающую содержимое изображения простым английским языком. Вы научитесь загружать и запускать эти предобученные модели в PyTorch и познакомитесь с PyTorch Hub — набором инструментов, позволяющим с помощью единого интерфейса легко создавать модели PyTorch, подобные тем, которые мы будем обсуждать. А еще мы затронем источники данных, дадим определения таким терминам, как «метка» и, посетим родео с зебрами.
Если вы переходите на PyTorch с другого фреймворка глубокого обучения и хотели бы непосредственно заняться практикой, можете сразу читать главу 3. Здесь мы рассмотрим скорее развлекательные, чем серьезные вопросы, причем практически общие для всех утилит глубокого обучения. Это не значит, что они неважны! Но если вы уже работали с предобученными моделями в других фреймворках глубокого обучения, то прекрасно знаете, какие обширные возможности они открывают. А если вы уже знакомы с генеративными состязательными сетями (GAN), то вам не будет интересен наш подробный рассказ о них. Впрочем, мы надеемся, что вы продолжите чтение этой главы, поскольку в ней описываются довольно важные навыки. Умение работать с предобученными моделями с помощью PyTorch — полезный навык и точка! Особенно он полезен, если модель обучена на большом наборе данных. Нам нужно будет привыкнуть к специфике получения и запуска нейронной сети на реальных данных, а также последующей визуализации и оценки результатов ее работы вне зависимости от того, обучали мы ее или нет.
2.1. Предобученные сети для распознавания тематики изображения
В качестве первого экскурса в глубокое обучение запустим современную глубокую нейронную сеть, предобученную на задаче распознавания образов. В репозиториях исходного кода доступно множество предобученных сетей. Исследователи часто публикуют свой исходный код вместе со статьями, причем нередко в код включаются весовые коэффициенты, полученные при обучении модели на эталонном наборе данных. С помощью одной из таких моделей можно, например, без особых усилий оснастить веб-сервис возможностями распознавания изображений.
Предобученная сеть, которую мы здесь будем изучать, обучена на подмножестве набора данных ImageNet. ImageNet — очень большой набор данных из более чем 14 миллионов изображений, поддерживаемый Стэнфордским университетом. Все его изображения маркированы при помощи иерархии существительных из набора данных WordNet — большой лексической базы данных английского языка.
Набор данных ImageNet, подобно нескольким другим общедоступным наборам данных, появился в результате научных конкурсов. Такие конкурсы традиционно служат одними из главных площадок соревнования исследователей из различных учреждений и компаний. В частности, с момента своего появления в 2010 году большую популярность обрел конкурс крупномасштабных распознаваний зрительных образов ImageNet (ImageNet Large Scale Visual Recognition Challenge, ILSVRC). Этот конкретный конкурс включает в себя несколько заданий, меняющихся от года к году, например классификацию изображений (выяснение, какие категории объектов содержит изображение), локализацию объектов (определение местоположения объектов на изображении), обнаружение объектов (выявление и маркирование объектов на изображениях), классификацию обстановки (классификация общего плана на изображении) и разбор обстановки (разбиение изображения на области, относящиеся к различным семантическим категориям, например «корова», «дом», «сыр», «шляпа»). В частности, задача классификации изображений состоит в получении на основе входного изображения списка из пяти описывающих содержимое изображения меток (из общего списка в 1000 категорий), отсортированных по степени достоверности.
Обучающий набор данных для ILSVRC состоит из 1,2 миллиона изображений, маркированных одним из 1000 существительных (например, «собака») — классов изображений. Мы будем использовать далее в этом значении попеременно термины «метка» (label) и «класс» (class). На рис. 2.1 приведены некоторые из изображений ImageNet.

В конечном итоге мы хотим подавать свои собственные изображения на вход предобученной модели, как показано на рис. 2.2. В результате мы получим список прогнозируемых меток для этого изображения, по которым затем сможем понять, что наша модель думает о конкретном изображении. Предсказания для некоторых изображений безошибочны, а для других — нет!
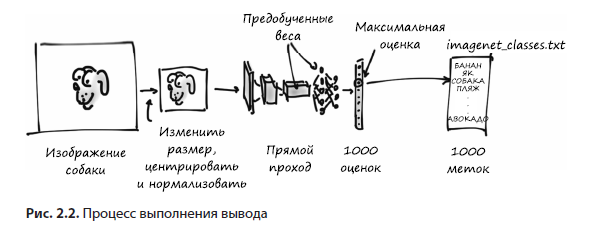
Входное изображение сначала необходимо предварительно обработать, превратив в экземпляр класса многомерного массива torch.Tensor. Для изображения RGB с высотой и шириной тензор будет включать три измерения: три цветовых канала и два пространственных измерения заданного размера (в главе 3 мы обсудим подробнее, что представляет собой этот тензор, а пока что можете просто считать его чем-то наподобие вектора или матрицы чисел с плавающей запятой). Наша модель принимает на входе это обработанное входное изображение и передает его предобученной сети, возвращающей оценки для всех классов. Наивысшая оценка соответствует наиболее вероятному классу в зависимости от веса. После этого каждый класс сопоставляется со своей меткой класса. Выходной сигнал содержится в torch.Tensor из 1000 элементов, каждый из которых соответствует оценке для конкретного класса.
Прежде чем заняться всем этим, необходимо получить саму нейронную сеть, заглянуть ей «под капот», чтобы понять, как она устроена, и разобраться с подготовкой данных для использования моделью.
2.1.1. Получение предобученной сети для распознавания изображений
Как мы уже упоминали, сейчас мы вооружимся нейронной сетью, обученной на ImageNet. Для этого взглянем на проект TorchVision, включающий несколько лучших нейросетевых архитектур, предназначенных для машинного зрения: AlexNet, ResNet и Inception v3. Он также обеспечивает удобный доступ к таким наборам данных, как ImageNet, и прочим инструментам для работы с машинным зрением в PyTorch. Мы обсудим часть из них подробнее далее в этой книге. А пока что просто загрузим и запустим две сети: сначала AlexNet, одну из первых инновационных сетей для распознавания изображений; а затем остаточную сеть (residual network, сокращенно — ResNet), выигравшую, помимо прочего, в 2015 году конкурсы ImageNet по классификации, обнаружению и локализации. Если вы не установили и не настроили PyTorch в главе 1 — самое время это сделать.
Найти предобученные модели можно в torchvision.models (code/p1ch2/2_pre_trained_networks.ipynb):
# In[1]:
from torchvision import models
Взглянем на сами модели:
# In[2]:
dir(models)
# Out[2]:
['AlexNet',
'DenseNet',
'Inception3',
'ResNet',
'SqueezeNet',
'VGG',
...
'alexnet',
'densenet',
'densenet121',
...
'resnet',
'resnet101',
'resnet152',
...
]
Названия, начинающиеся с заглавной буквы, относятся к классам Python, реализующим несколько популярных моделей, отличающихся архитектурой, то есть схемой операций между входом и выходом модели. Названия в нижнем регистре — вспомогательные функции, возвращающие созданные на основе этих классов модели, иногда с различными наборами параметров. Например, resnet101 возвращает экземпляр ResNet со 101 слоем, resnet18 содержит 18 слоев и т. д. Сначала мы займемся AlexNet.
2.1.2. AlexNet
В 2012 году архитектура AlexNet с большим отрывом от соперников выиграла конкурс ILSVRC с частотой ошибок топ-5 (коэффициент правильных ошибок) (то есть с наличием правильной метки в пяти лучших предсказаниях) в 15,4 %. Для сравнения: занявшая второе место архитектура, не основанная на нейронных сетях, показала результат лишь 26,2 %. Это был поворотный момент в истории машинного зрения: момент, когда сообщество стало осознавать потенциал глубокого обучения для задач машинного зрения. За этим прорывом последовал период непрерывного совершенствования, и теперь у наиболее современных архитектур и методов обучения частота ошибок топ-5 составляет всего 3 %.
По сегодняшним меркам AlexNet довольно небольшая сеть по сравнению с современными моделями. Но в нашем случае она прекрасно подходит, чтобы познакомиться с реально работающей нейронной сетью и научиться запускать ее предобученную версию для нового изображения.
Структура AlexNet приведена на рис. 2.3. Конечно, пока мы еще не знаем всего, что требуется для ее понимания, но кое-что можно сказать уже сейчас.

Прежде всего, каждый из блоков включает в себя набор операций умножения и сложения, а также небольшое количество прочих функций, как мы увидим в главе 5. Это можно считать своего рода фильтром — функцией, получающей на входе одно или несколько изображений и генерирующей в качестве выходного сигнала другие изображения. Конкретный способ определяется во время обучения на основе просмотренных моделью примеров данных, а также желаемых выходных сигналов для них.
На рис. 2.3 входные изображения поступают слева и проходят через пять комплектов фильтров, каждый из которых формирует некоторое количество выходных изображений. С каждым фильтром изображения уменьшаются в размере. Полученные последним комплектом фильтров изображения представляются в виде одномерного вектора из 4096 элементов и классифицируются, в результате чего генерируется 1000 выходных значений вероятности, по одному для каждого выходного класса.
Для запуска архитектуры AlexNet на каком-либо входном изображении необходимо создать экземпляр класса AlexNet. Вот таким образом:
# In[3]:
alexnet = models.AlexNet()
На этом этапе alexnet представляет собой объект, подходящий для выполнения архитектуры AlexNet. Понимание всех нюансов данной архитектуры нам сейчас не требуется. Пока что alexnet для нас представляет собой просто некий объект — «черный ящик», который можно запускать как функцию. Подав на вход alexnet входные данные четко определенного размера, мы выполним прямой проход (forward pass) по сети, при котором входной сигнал пройдет через первый набор нейронов, выходные сигналы которых будут поданы на вход следующего набора нейронов, и так до самого итогового выходного сигнала. На практике это означает, что при наличии объекта input нужного типа можно произвести прямой проход с помощью оператора output = alexnet(input).
Но если мы так поступим, то пропустим данные через всю сеть лишь для того, чтобы получить… мусор! А все потому, что сеть не была инициализирована: ее веса, числа, с которыми складываются и на которые умножаются входные сигналы, не были обучены на чем-либо, сеть сама по себе — чистый (или, точнее, случайный) лист. Необходимо либо обучить ее с нуля, либо загрузить веса, полученные в результате предыдущего обучения, что мы сейчас и сделаем.
Для этого вернемся к модулю models. Мы уже знаем, что названия в верхнем регистре соответствуют классам, реализующим популярные архитектуры, предназначенные для машинного зрения. С другой стороны, названия в нижнем регистре соответствуют функциям, создающим экземпляры моделей с заранее определенным количеством слоев и нейронов, а также, возможно, скачивающие и загружающие в них предобученные веса. Обратите внимание, что эти функции несущественны, они просто упрощают создание экземпляра модели с соответствующим предобученной сети количеством слоев и нейронов.
2.1.3. ResNet
Сейчас с помощью функции resnet101 мы создадим экземпляр сверточной нейронной сети из 101 слоя. Для наглядности: до появления остаточных нейронных сетей в 2015-м считалось, что добиться настолько устойчивого обучения при подобной глубине сети чрезвычайно сложно. Остаточные нейронные сети ухитрились сделать это возможным и тем самым побили несколько рекордов за один раз.
Создадим теперь экзепляр данной сети. Для этого мы передадим нашей функции аргумент, который укажет ей скачать веса resnet101, обученные на наборе данных ImageNet, включающем 1,2 миллиона изображений и 1000 категорий:
# In[4]:
resnet = models.resnet101(pretrained=True)
Пока мы смотрим на процесс загрузки, оцените тот факт, что resnet101 может похвастаться 44,5 миллиона параметров — огромное количество для автоматической оптимизации!
2.1.4. На старт, внимание, почти что марш
Хорошо, что же мы только что сделали? Раз уж нам так интересно, можно взглянуть одним глазом, что представляет собой resnet101. Для этого можно вывести на экран значение возвращаемой модели и получить текстовое представление информации, аналогичной той, что мы видели в разделе 2.3, со всеми подробностями о структуре сети. На данный момент нам столько информации не нужно, но по мере чтения книги вы постепенно начнете понимать, что этот код нам говорит:
# In[5]:
resnet
# Out[5]:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3),
bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1,
ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
...
)
)
(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
Здесь мы видим modules, по одному на строку. Обратите внимание, что ничего общего с модулями Python у них нет: это отдельные операции, «кирпичики» нейронной сети. В других фреймворках глубокого обучения их также называют слоями (layers).
Если прокрутить вниз, можно увидеть множество модулей Bottleneck, один за другим (всего 101!), содержащих операции свертки и прочие модули. Именно так и устроена типичная глубокая нейронная сеть для машинного зрения: более или менее последовательный каскад фильтров и нелинейных функций, завершающийся слоем (fc), генерирующим оценки для каждого из 1000 выходных классов (out_features).
Переменную resnet можно вызывать как функцию, при этом она принимает на входе одно или несколько изображений и генерирует соответствующее количество оценок для каждого из классов ImageNet. Перед этим, впрочем, необходимо предварительно привести входные изображения к нужному размеру, а их значения (цвета) примерно в один числовой диапазон. Для этого модуль torchvision предоставляет преобразования (transforms), позволяющие быстро описывать конвейеры простейших операций предварительной обработки:
# In[6]:
from torchvision import transforms
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)])
Здесь мы описали функцию preprocess, масштабирующую входное изображение до размера 256 × 256, обрезающую его до 224 × 224 по центру, преобразующую в тензор (многомерный массив PyTorch: в данном случае трехмерный массив, содержащий цвет, высоту и ширину) и нормализующую его компоненты RGB (красный, зеленый, синий) до заданных среднего значения и стандартного отклонения. Если мы хотим получить от сети осмысленные ответы, все это должно соответствовать данным, полученным сетью во время обучения. Мы обсудим преобразования подробнее, когда будем создавать свои собственные модели распознавания изображений в подразделе 7.1.3.
Возьмем теперь изображение нашей любимой собаки (bobby.jpg из репозитория GitHub), проведем предварительную обработку и посмотрим, что о нем думает модель ResNet. Начнем с загрузки изображения из локальной файловой системы с помощью Pillow (https://pillow.readthedocs.io/en/stable) — модуля Python для обработки изображений:
# In[7]:
from PIL import Image
img = Image.open("../data/p1ch2/bobby.jpg")
Если вы работаете с блокнотом Jupyter, то, чтобы посмотреть в нем это изображение, необходимо выполнить следующую команду (изображение будет показано на месте <PIL.JpegImagePlugin…):
# In[8]:
img
# Out[8]:
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=1280x720 at
0x1B1601360B8>
Либо можно вызвать метод show, при этом всплывет окошко с программой просмотра, в которой будет показано изображение с рис. 2.4.

Далее можно пропустить это изображение через наш конвейер предварительной обработки:
# In[9]:
img_t = preprocess(img)
При этом можно изменять размер изображения, обрезать его и нормализовывать входной тензор так, как нужно сети. Мы поговорим об этом подробнее в следующих двух главах; а пока что держитесь крепче:
# In[10]:
import torch
batch_t = torch.unsqueeze(img_t, 0)
Все готово к запуску модели.
2.1.5. Марш!
Процесс выполнения обученной модели на новых данных в сфере глубокого обучения называется выводом (inference). Для выполнения вывода необходимо перевести сеть в режим eval:
# In[11]:
resnet.eval()
# Out[11]:
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3),
bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
(relu): ReLU(inplace)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1,
ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
...
)
)
(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
Если забыть сделать это, некоторые предобученные модели, например включающие нормализацию по мини-батчам и дропаут, не дадут никаких осмысленных результатов просто по причине их внутреннего устройства. Теперь, после установки режима eval, можно выполнять вывод:
# In[12]:
out = resnet(batch_t)
out
# Out[12]:
tensor([[ -3.4803, -1.6618, -2.4515, -3.2662, -3.2466, -1.3611,
-2.0465, -2.5112, -1.3043, -2.8900, -1.6862, -1.3055,
...
2.8674, -3.7442, 1.5085, -3.2500, -2.4894, -0.3354,
0.1286, -1.1355, 3.3969, 4.4584]])
Только что было выполнено ошеломляющее количество операций с 44,5 миллиона параметров, был сгенерирован вектор с 1000 оценок, по одной для каждого класса ImageNet. Это не заняло много времени, не правда ли?
Теперь нужно определить метку класса, получившую максимальную оценку, и это расскажет нам о том, что модель увидела на рисунке. Если метка соответствует тому, как это изображение описал бы человек, — замечательно, значит, модель работает! Если же нет, значит, что-то пошло не так во время обучения, или изображение настолько отличается от ожидаемого моделью, что она не смогла обработать его должным образом, или возникла еще какая-либо аналогичная проблема.
Для просмотра списка предсказанных меток загрузим текстовый файл, в котором метки перечислены в том же порядке, в каком их видела сеть во время обучения, а затем возьмем метку, соответствующую максимальной оценке сети. Форма выходного сигнала практически всех моделей, предназначенных для распознавания изображений, аналогична той, с которой мы сейчас будем работать.
Загрузим файл с 1000 меток для классов набора данных ImageNet:
# In[13]:
with open('../data/p1ch2/imagenet_classes.txt') as f:
labels = [line.strip() for line in f.readlines()]
Теперь нам нужно найти в полученном ранее тензоре out индекс, соответствующий максимальной оценке. Для этого воспользуемся функцией max PyTorch, возвращающей максимальное значение в тензоре, а также соответствующие ему индексы:
# In[14]:
_, index = torch.max(out, 1)
Сейчас можно получить доступ к метке по этому индексу. В данном случае index представляет собой не просто числовое значение Python, а состоящий из одного элемента одномерный тензор (а именно tensor([207])), так что необходимо получить числовое значение, которым мы могли бы воспользоваться в качестве индекса в нашем списке labels с помощью синтаксиса index[0]. Мы также воспользуемся torch.nn.functional.softmax для нормализации выходных сигналов к диапазону [0, 1] и деления на их сумму. В результате мы получим что-то вроде меры уверенности модели в конкретном предсказании. В данном случае модель на 96 % уверена, что видит перед собой золотистого ретривера:
# In[15]:
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
labels[index[0]], percentage[index[0]].item()
# Out[15]:
('golden retriever', 96.29334259033203)
О-о, кто у нас тут хороший мальчик?
Поскольку модель генерирует оценки, мы можем также узнать занимающую второе место, третье и т. д. Для этого можно воспользоваться функцией sort, сортирующей значения в порядке возрастания или убывания, а также возвращающей индексы отсортированных значений в исходном массиве:
# In[16]:
_, indices = torch.sort(out, descending=True)
[(labels[idx], percentage[idx].item()) for idx in indices[0][:5]]
# Out[16]:
[('golden retriever', 96.29334259033203),
('Labrador retriever', 2.80812406539917),
('cocker spaniel, English cocker spaniel, cocker', 0.28267428278923035),
('redbone', 0.2086310237646103),
('tennis ball', 0.11621569097042084)]
Как видим, первые четыре — собаки (редбон — тоже порода собак, кто бы мог подумать?), после чего начинается странное. Пятый ответ, «теннисный мяч», возможно, возник потому, что существует столько фотографий теннисных мячей с собаками неподалеку, что модель фактически говорит нам: «С вероятностью 0,1 % я совершенно неправильно понимаю, что такое теннисный мяч». Это прекрасный пример принципиальных расхождений во взгляде на мир людей и нейронных сетей, а также насколько легко в наши данные могут закрасться странные, малозаметные систематические ошибки.
Пора поэкспериментировать! Подадим на вход нашей сети различные случайные изображения и посмотрим, что она нам вернет. Успешность работы сети во многом зависит от наличия соответствующих объектов в обучающем наборе данных. Если подать нейронной сети нечто выходящее за рамки обучающего набора данных, вполне возможно, что она достаточно уверенно вернет неправильный ответ.
Мы просто запустили сеть, выигравшую конкурс по классификации изображений в 2015 году. Она научилась на примерах различных собак узнавать нашу собаку, а также множество прочих объектов реального мира. Теперь мы узнаем, как различные архитектуры могут решать и прочие виды задач, начиная с генерации изображений.
Лука Антига работал исследователем в сфере биоинженерии в 2000-х годах, а последнее десятилетие играл роль одного из основателей и технического директора компании, занимающейся проектированием систем искусственного интеллекта. Он участвовал в нескольких проектах с открытым исходным кодом, включая ядро PyTorch.
Томас Виман — инструктор и консультант по машинному обучению и PyTorch, проживающий в Мюнхене, а также разработчик ядра PyTorch. Как обладатель докторской степени по математике, он не боится теории, но подходит с практической стороны, применяя ее к сложным вычислительным задачам.
Подробнее с книгой можно ознакомиться в нашем каталоге.
Комментарии: 0
Пока нет комментариев