



Новости

15.09.2020
Книга «Программируем с PyTorch: Создание приложений глубокого обучения»
Вы научитесь: — Внедрять модели глубокого обучения в работу — Использовать PyTorch в масштабных проектах — Применять перенос обучения — Использовать PyTorch torchaudio и сверточные модели для классификации аудиоданных — Применять самые современные методы NLP, используя модель, обученную на «Википедии» — Выполнять отладку моделей PyTorch с TensorBoard и флеймграф — Развертывать приложения PyTorch в контейнерах «PyTorch –– это одна из самых быстрорастущих библиотек глубокого обучения, соперничающая с гигантом Google — TensorFlow — практически на равных.
Классификация изображений с помощью PyTorch
Учебники по глубокому обучению пестрят профессиональной непонятной терминологией. Я стараюсь свести ее к минимуму и всегда приводить один пример, который можно легко расширить, когда вы привыкнете работать с PyTorch. Мы используем этот пример на протяжении всей книги, чтобы продемонстрировать, как отладить модель (глава 7) или развернуть ее в рабочей среде (глава 8).
С этого момента и до конца главы 4 мы будем компилировать классификатор изображений. Нейронные сети обычно используются в качестве классификаторов изображений; сети предлагают картинку и задают простой вопрос: «Что это?».
Давайте начнем с создания нашего приложения в PyTorch.
Проблема классификации
Здесь мы создадим простой классификатор, который может отличить рыбку от кошки. Мы будем итерировать дизайн и процесс разработки нашей модели, чтобы сделать ее более точной.
На рис. 2.1 и 2.2 изображены рыбка и кошка во всей своей красе. Не уверен, есть ли у рыбки имя, а вот кошку зовут Гельветика.
Давайте начнем с обсуждения стандартных проблем, связанных с классификацией.

Стандартные трудности
Как написать программу, которая сможет отличить рыбку от кошки? Возможно, вы бы написали набор правил, описывающих, что у кошки есть хвост или что у рыбки есть чешуя, и применили бы эти правила к изображению, чтобы программа классифицировала изображение. Но для этого потребуется время, усилия и навыки. А что делать, если вам попадется мэнская кошка? Хотя это явно кошка, у нее нет хвоста.
Эти правила становятся все сложнее и сложнее, когда вы пытаетесь с их помощью описать все возможные сценарии. Кроме того, должен признаться, что визуальное программирование у меня выходит кошмарно, поэтому мысль о необходимости вручную писать код для всех этих правил приводит в ужас.
Нужна функция, которая при вводе изображения возвращает кошку или рыбку. Сложно построить такую функцию, просто перечислив полностью все критерии. Но глубокое обучение, по сути, заставляет компьютер выполнять тяжелую работу по созданию всех этих правил, о которых мы только что говорили, при условии, что мы создаем структуру, предоставляем сети много данных и даем ей возможность понять, правильный ли ответ она дала. Именно это мы собираемся сделать. Кроме того, вы узнаете некоторые основные методы использования PyTorch.
Но сначала данные
Для начала нам нужны данные. Сколько данных? Зависит от разных факторов. Как вы увидите в главе 4, идея о том, что для работы любой техники глубокого обучения нужны огромные объемы данных для обучения нейронной сети, не обязательно верна. Однако сейчас мы собираемся начинать с нуля, что обычно требует доступа к большому количеству данных. Требуется много изображений рыбок и кошек.
Можно было бы потратить какое-то время на загрузку кучи изображений из поиска изображений в Google, но есть более легкий путь: стандартная коллекция изображений, используемая для обучения нейронных сетей, — ImageNet. Она содержит более 14 миллионов изображений и 20 тысяч категорий изображений. Это стандарт, по которому все классификаторы изображений проводят сравнение. Поэтому я беру изображения оттуда, хотя, если хотите, то можете выбрать другие варианты.
Кроме данных у PyTorch должен быть способ определить, что такое кошка и что такое рыбка. Это достаточно просто для нас, но для компьютера задача сложнее (именно поэтому мы и создаем программу!). Мы используем маркировку, прикрепленную к данным, и такое обучение называется машинное обучение с учителем. (Если у вас нет доступа к каким-либо маркировкам, то используется, как вы наверняка догадались, машинное обучение без учителя.)
Если мы используем данные ImageNet, их маркировки не будут полезными, потому что содержат слишком много информации. Маркировка полосатого кота или форели для компьютера — не то же самое, что кот или рыбка.
Требуется перемаркировать их. Поскольку ImageNet представляет собой обширную коллекцию изображений, я собрал URL-адреса изображений и маркировки рыбок и кошек (https://oreil.ly/NbtEU).
Вы можете запустить скрипт download.py в этом каталоге, и он загрузит изображения с URL-адресов и разместит их в соответствующих местах для обучения. Перемаркировка проста; скрипт хранит изображения кошек в каталоге train/cat и изображения рыбок в каталоге train/fish. Если не хотите использовать скрипт для загрузки, просто создайте эти каталоги и разместите соответствующие изображения в нужных местах. Теперь у нас есть данные, но нужно преобразовать их в формат, понятный PyTorch.
PyTorch и загрузчики данных
Загрузка и преобразование данных в готовые к обучению форматы часто оказываются одной из областей data science, которая отнимает слишком много времени. PyTorch разработал установленные требования взаимодействия с данными, которые делают его довольно понятным, независимо от того, работаете ли вы с изображениями, текстом или аудио.
Двумя основными условиями работы с данными являются наборы данных и загрузчики данных. Набор данных — это класс Python, позволяющий получать данные, которые мы отправляем в нейронную сеть.
Загрузчик данных — это то, что передает данные из набора данных в сеть. (Может включать в себя такую информацию, как: Сколько рабочих процессов передают данные в сеть? Сколько изображений мы передаем одновременно?)
Давайте сначала посмотрим на набор данных. Каждый набор данных, независимо от того, содержит ли он изображения, аудио, текст, 3D-ландшафты, информацию о фондовом рынке или что-либо еще, может взаимодействовать с PyTorch, если отвечает требованиям этого абстрактного класса Python:
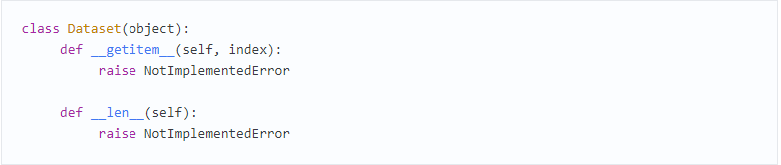
Это довольно просто: мы должны воспользоваться методом, который возвращает размер нашего набора данных (len), и тем, который может извлечь элемент из набора данных в паре (label, tensor). Это вызывается загрузчиком данных, поскольку передает данные в нейронную сеть для обучения. Таким образом, мы должны написать тело для метода getitem, которое может взять изображение, преобразовать его в тензор и вернуть его и маркировку обратно, чтобы PyTorch мог с ним работать. Все понятно, но, очевидно, этот сценарий встречается достаточно часто, так что, может быть, PyTorch облегчит задачу?
Создание обучающего набора данных
В пакет torchvision включен класс ImageFolder, который делает практически все, при условии, что наши изображения находятся в структуре, где каждый каталог представляет собой маркировку (например, все кошки находятся в каталоге с именем cat). Вот что нужно для примера с кошками и рыбками:
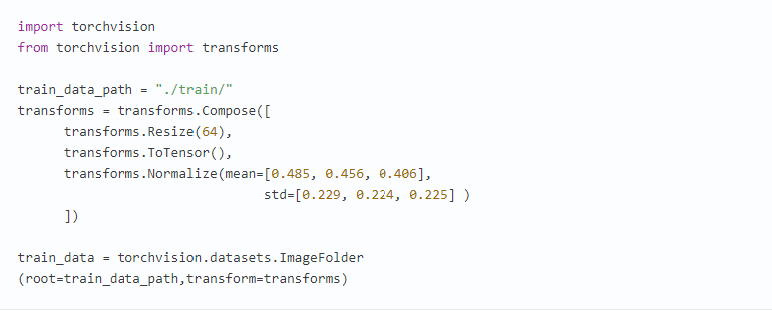
Здесь добавляется кое-что еще, потому что torchvision также позволяет указать список преобразований, которые будут применены к изображению, прежде чем оно попадет в нейронную сеть. Преобразование по умолчанию состоит в том, чтобы взять данные изображения и превратить их в тензор (метод trans forms.ToTensor(), показанный в предыдущем коде), но также выполняется несколько других действий, которые могут быть не такими очевидными.
Во-первых, GPU созданы для быстрого выполнения вычислений стандартного размера. Но у нас, вероятно, есть ассортимент изображений во многих разрешениях. Чтобы повысить производительность обработки, мы масштабируем каждое входящее изображение до того же разрешения 64 × 64 с помощью преобразования Resize (64). Затем конвертируем изображения в тензор и, наконец, нормализуем тензор вокруг определенного набора средних и стандартных точек отклонения.
Нормализация важна, поскольку предполагается выполнение большого количества операций умножения, когда входные данные проходят через слои нейронной сети; поддержание входящих значений от 0 до 1 предотвращает серьезное увеличение значений во время фазы обучения (известное как проблема взрывающихся градиентов). Это волшебное воплощение — всего лишь среднее и стандартное отклонение набора данных ImageNet в целом. Можно рассчитать его специально для подмножества рыбок и кошек, но эти значения достаточно надежны. (Если бы вы работали над совершенно другим набором данных, нужно было бы вычислить это среднее значение и отклонение, хотя многие просто используют константы ImageNet и сообщают о приемлемых результатах.)
Компонуемые преобразования также позволяют легко выполнять такие действия, как поворот и сдвиг изображения для аугментации данных, к которой мы вернемся в главе 4.
В этом примере мы изменяем размеры изображений до 64 × 64. Я сделал такой случайный выбор, чтобы ускорить вычисления в нашей первой сети. Большинство существующих архитектур, которые вы увидите в главе 3, используют для своих входных изображений разрешение 224 × 224 или 299 × 299.. Как правило, чем больше размер входного файла, тем больше данных, по которым сеть может обучаться.. Обратная сторона медали в том, что обычно можно разместить меньшую партию изображений в памяти GPU.
О наборах данных есть множество другой информации, и это далеко не все. Но зачем нам знать больше, чем нужно, если мы уже знаем о наборе данных для обучения?
С полным содержанием статьи можно ознакомиться на сайте "Хабрахабр": https://habr.com/ru/company/piter/blog/512158/
Комментарии: 0
Пока нет комментариев