


Новости

24.08.2020
Книга «Обработка естественного языка в действии»
Книга ориентирована на Python-разработчиков среднего и высокого уровня. Значительная часть книги будет полезна и тем читателям, которые уже умеют проектировать и разрабатывать сложные системы, поскольку в ней содержатся многочисленные примеры рекомендуемых решений и раскрываются возможности самых современных алгоритмов NLP. Хотя знание объектно-ориентированного программирования на Python может помочь создавать лучшие системы, для использования приводимой в этой книге информации оно не обязательно.
Нейронные сети с обратной связью: рекуррентные нейронные сети
В главе 7 продемонстрированы возможности анализа фрагмента или целого предложения с помощью сверточной нейронной сети, отслеживание соседних слов в предложении путем наложения на них фильтра разделяемых весов (выполнения свертки). Встречающиеся группами слова можно также обнаруживать в связке. Сеть также устойчива к небольшим смещениям позиций этих слов. В то же время встречающиеся по соседству понятия могут существенно влиять на сеть. Но если нужно охватить взглядом большую картину происходящего, учесть взаимосвязи за более длительный промежуток времени, окно, охватывающее больше 3–4 токенов из предложения? Как ввести в сеть понятие произошедших ранее событий? Память?
Для каждого тренировочного примера (или батча неупорядоченных примеров) и выходного сигнала (или пакета выходных сигналов) нейронной сети прямого распространения веса нейронной сети необходимо откорректировать для отдельных нейронов на основе метода обратного распространения ошибки. Это мы уже демонстрировали. Но результаты этапа обучения для следующего примера в основном не зависят от порядка входных данных. Сверточные нейронные сети стремятся захватить эти отношения порядка за счет захвата локальных взаимосвязей, но существует и другой способ.
В сверточной нейронной сети каждый тренировочный пример передается сети в виде сгруппированного набора токенов слов. Векторы слов сгруппированы в матрицу в форме (длина вектора слова × число слов в примере), как показано на рис. 8.1.

Но эту последовательность векторов слов можно столь же легко передать и обычной нейронной сети прямого распространения из главы 5 (рис. 8.2), правда?
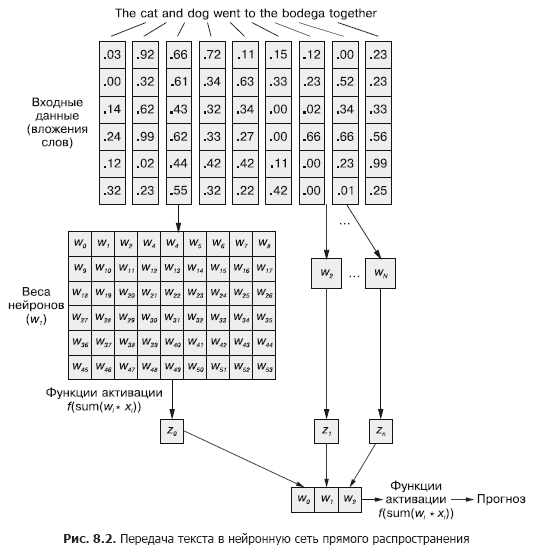
Безусловно, это вполне работоспособная модель. При подобном способе передачи входных данных нейронная сеть прямого распространения сможет реагировать на совместные вхождения токенов, что нам и нужно. Но она будет при этом реагировать на все совместные вхождения одинаково, независимо от того, разделяет ли их длинный текст, или они находятся рядом друг с другом. Кроме того, нейронные сети прямого распространения, как и CNN, плохо умеют обрабатывать документы переменной длины. Они не способны обработать текст в конце документа, если он выходит за пределы ширины сети.
Лучше всего нейронные сети прямого распространения проявляют себя в моделировании взаимосвязи выборки данных в целом с соответствующей ей меткой. Слова в начале и в конце предложения ровно так же влияют на выходной сигнал, как и посередине, невзирая на то что вряд ли они семантически связаны друг с другом.
Подобная однородность (равномерность влияния) явно может вызывать проблемы в случае, например, токенов резкого отрицания и модификаторов (прилагательных и наречий), таких как «нет» или «хороший». В нейронной сети прямого распространения выражающие отрицание слова влияют на смысл всех слов в предложении, даже сильно удаленных от места, на которое они должны влиять на самом деле.
Одномерные свертки — способ решения проблем с этими взаимосвязями между токенами путем анализа нескольких слов через окна. Обсуждавшиеся в главе 7 слои субдискретизации специально предназначены для учета небольших изменений порядка слов. В этой главе мы рассмотрим другой подход, благодаря которому сможем сделать первый шаг к понятию памяти нейронной сети. Вместо того чтобы разбирать язык как большую порцию данных, мы начнем рассматривать его последовательное формирование, токен за токеном, с ходом времени.
8.1. Запоминание в нейронных сетях
Конечно, слова в предложении редко бывают совершенно независимыми друг от друга; их вхождения влияют или подвергаются влиянию вхождений других слов в документе. Например: The stolen car sped into the arena и The clown car sped into the arena.
У вас могут возникнуть совершенно различные впечатления от этих двух предложений, когда вы дочитаете до конца. Конструкция фразы в них одинакова: прилагательное, существительное, глагол и предложный оборот. Но замена прилагательного в них радикальным образом меняет суть происходящего с точки зрения читателя.
Как смоделировать подобную взаимосвязь? Как понять, что arena и даже sped могут иметь немного разные коннотации, если перед ними в предложении есть прилагательное, не являющееся прямым определением ни одного из них?
Если бы существовал способ запоминать произошедшее моментом ранее (особенно помнить на шаге t + 1 произошедшее на шаге t), можно было бы выявлять закономерности, возникающие при появлении определенных токенов в связанных с другими токенами последовательности закономерностях. Рекуррентные нейронные сети (RNN) как раз делают возможным запоминание нейронной сетью прошлых слов последовательности.
Как вы видите на рис. 8.3, отдельный рекуррентный нейрон из скрытого слоя добавляет в сеть рекуррентный цикл для «повторного использования» выходного сигнала скрытого слоя для момента t. Выходной сигнал для момента t прибавляется к следующему входному сигналу для момента t + 1. В результате обработки сетью этого нового входного сигнала на временном шаге t + 1 получается выходной сигнал скрытого слоя для момента t + 1. Этот выходной сигнал для момента времени t + 1 далее повторно используется сетью и включается во входной сигнал на временном шаге t + 2 и т. д.
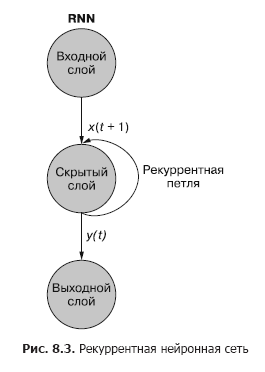
Хотя идея воздействия на состояние сквозь время выглядит немного запутанной, основная концепция проста. Результаты каждого сигнала на входе обычной нейронной сети прямого распространения на временном шаге t используются в качестве дополнительного входного сигнала вместе со следующим фрагментом подаваемых на вход сети данных на временном шаге t + 1. Сеть получает информацию не только о происходящем сейчас, но и о происходившем ранее.
В этой и следующей главах большая часть нашего обсуждения происходит на языке временных шагов. Это вовсе не то же самое, что отдельные примеры данных. Речь идет о разбиении одного примера данных на меньшие порции, отражающие изменения во времени. Этот отдельный пример данных все равно представляет собой фрагмент текста, скажем короткий отзыв о фильме или твит. Как и ранее, мы токенизируем предложение. Но вместо того, чтобы отправлять токены в сеть все сразу, мы передаем их по одному. Эта схема отличается от передачи нескольких новых примеров документов. Токены при этом остаются частью одного примера данных, которому соответствует одна метка.
t можно считать индексом последовательности токенов. Так, t = 0 — первый токен в документе, а t + 1 — следующий. Токены в порядке следования их в документе служат входными сигналами на каждом из временных (токенных) шагов. Причем токены не обязательно должны быть словами, отдельные символы также допустимы. Подача примера данных в сеть разбивается на подшаги — ввод в сеть отдельных токенов.
На протяжении всей этой книги мы будем обозначать текущий временной шаг t, а следующий временной шаг — t + 1.
Рекуррентную нейронную сеть можно визуализировать так, как показано на рис. 8.3: круги соответствуют целым слоям нейронной сети прямого распространения, состоящим из одного или нескольких нейронов. Выходной сигнал скрытого слоя выдается сетью как обычно, но затем поступает обратно в качестве своего же (скрытого слоя) входного сигнала вместе с обычными входными данными следующего временного шага. На схеме этот цикл обратной связи изображен в виде дуги, ведущей из выхода слоя обратно на вход.
Более простой (и чаще используемый) способ иллюстрации этого процесса — с использованием развертывания сети. Рисунок 8.4 демонстрирует сеть «вверх ногами» с двумя развертками временной переменной (t) — слоями для шагов t + 1 и t + 2.
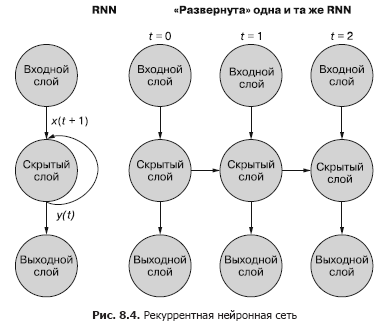
Каждому из временных шагов соответствует развернутая версия той же нейронной сети в виде столбца нейронов. Это все равно, что смотреть сценарий или отдельные видеокадры нейронной сети в каждый момент времени. Сеть справа представляет собой будущую версию сети слева. Выходной сигнал скрытого слоя в момент времени (t) подается снова на вход скрытого слоя вместе с входными данными для следующего временного шага (t + 1) справа. И еще раз. На схеме показаны две итерации этого развертывания, всего три столбца нейронов для t = 0, t = 1 и t = 2.
Все вертикальные маршруты на этой схеме полностью аналогичны, в них показаны одни и те же нейроны. Они отражают одну и ту же нейронную сеть в разные моменты времени. Такое наглядное представление удобно при демонстрации движения информации по сети в прямом и обратном направлении во время обратного распространения ошибки. Но помните, глядя на эти три развернутые сети: они представляют собой различные моментальные снимки одной и той же сети с тем же набором весов.
Изучим внимательнее исходное представление рекуррентной нейронной сети до ее развертывания и покажем взаимосвязи входных сигналов и весов. Отдельные слои этой RNN выглядят так, как показано на рис. 8.5 и 8.6.

У всех нейронов скрытого состояния есть по набору весов, применяемых к каждому из элементов каждого из входных векторов, как в обычной сети прямого распространения. Но в этой схеме появился и дополнительный набор обучаемых весов, которые применяются к выходным сигналам скрытых нейронов из предыдущего временного шага. Сеть путем обучения подбирает подходящие веса (важность) предыдущих событий при вводе последовательности токен за токеном.
У первого входного сигнала в последовательности нет «прошлого», так что скрытое состояние на шаге t = 0 получает нулевой входной сигнал от себя же с шага t – 1. Можно также для «заполнения» начального значения состояния сначала передать в сеть взаимосвязанные, но отдельные примеры данных, один за другим. Итоговый выходной сигнал каждого примера используется во входном сигнале t = 0 следующего примера данных. В посвященном сохранению состояния разделе в конце данной главы мы расскажем вам, как сохранять больше информации из набора данных с помощью альтернативных методик заполнения.
Вернемся к данным: представьте, что у вас есть набор документов, каждый из которых представляет собой маркированный пример. И вместо того, чтобы для каждого выборочного примера передавать набор векторов слов целиком в сверточную нейронную сеть, как в предыдущей главе (рис. 8.7), мы передаем пример данных в RNN по одному токену (рис. 8.8).

Мы передаем вектор слов для первого токена и получаем выходной сигнал нашей рекуррентной нейронной сети. Затем передаем второй токен, а вместе с ним — выходной сигнал от первого! После этого передаем третий токен вместе с выходным сигналом от второго! И так далее. Теперь в нашей нейронной сети существуют понятия «до» и «после», причины и следствия, некое, пусть и расплывчатое, представление о времени (см. рис. 8.8).
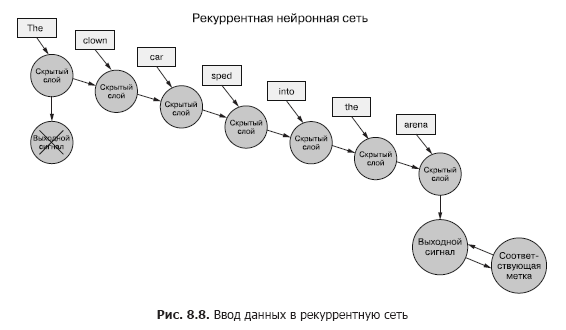
Теперь наша сеть уже кое-что запоминает! Ну, в известной мере. Осталось выяснить еще несколько вещей. Во-первых, как может происходить обратное распространение ошибки в подобной структуре?
С полным содержанием статьи можно ознакомиться на сайте "Хабрахабр": https://habr.com/ru/company/piter/blog/512790/
Комментарии: 0
Пока нет комментариев