



Новости

06.06.2022
Книга «Масштабируемый рефакторинг. Возвращаем контроль над кодом »
Поддерживать большие приложения сложно, а поддержка больших «неорганизованных» приложений превращается в непосильную задачу. Пришло время сделать паузу и задуматься о рефакторинге! Внесение значительных изменений в крупную и сложную кодовую базу — нетривиальная задача, которую практически невозможно успешно выполнить без рабочей команды, инструментов и планирования. Мод Лемер раскрывает все тайны рефакторинга на примере двух исследований. Вы научитесь эффективно вносить важные изменения в кодовую базу, узнаете, как деградирует код и почему иногда это неизбежно.
Рефакторингу посвящено уже много книг, но в большинстве из них рассматриваются детали улучшения небольших частей кода по строке за раз. Однако мне кажется, что самая сложная часть рефакторинга не в поиске точного способа улучшения кода, а скорее в происходящих вокруг него процессах. Можно пойти еще дальше и сказать, что для любого крупного программного проекта мелочи редко имеют значение. Самая большая проблема кроется в координации сложных изменений.
Переход к новой базе данных
Здесь мы рассмотрим рефакторинг, выполненный инженерами из группы разработки продукта и группы инфраструктуры в Slack. Основой для него послужила консолидация таблиц членства в каналах компании из прошлой главы. Если вы ее не прочти, советую сделать это сейчас. Там вы найдете важный контекст, необходимый для лучшего понимания этой главы.
Если в предыдущем случае рефакторинг проводился для увеличения производительности, теперь вопрос стоял об обеспечении большей гибкости продукта. Привязка членства в каналах к разным шардам рабочих пространств затрудняла создание более сложного функционала, выходящего за рамки одного рабочего пространства. Мы хотели позволить смешанным организационным структурам с несколькими рабочими пространствами беспрепятственно сотрудничать при одном наборе каналов и облегчить общение между отдельными клиентами Slack, позволяя компаниям договариваться с поставщиками в приложении. Для этого требовалось, чтобы шардирование данных о членстве в каналах выполнялось по пользователям и каналам, а не по рабочим пространствам. Крупномасштабная миграция баз данных, растянувшаяся на несколько кварталов и выполнявшаяся разными отделами, сопровождалась множеством проблем.
Тем не менее рефакторинг прошел успешно. Все четко понимали поставленную задачу и то, что продукт просто перерос нынешнее архитектурное решение в процессе развития (глава 2). Мы тщательно планировали проект и ввели в рассмотрение еще несколько переменных, зная, что это увеличит пользу от рефакторинга (глава 4). Была спланирована осторожная стратегия развертывания и разработаны инструменты для ее максимально надежной реализации (глава 8).
Хотя рефакторинг в конечном итоге позволил нам расширять наш продукт новыми и интересными способами, он занял почти вдвое больше времени, чем мы изначально планировали. Мы оказались слишком оптимистичными в оценках (глава 4). Потребовалось больше года для завершения проекта, изначально рассчитанного на шесть месяцев. Мы недооценили влияние рефакторинга на продукт и привлекли к сотрудничеству инженеров по продукту только после того, как несколько месяцев почти не двигались вперед (глава 6).
Как и в прошлой главе, я начну рассказ с краткого обзора ситуации. Он позволит лучше понять, почему способ распределения данных стал узким местом и почему мы решили перейти к новой системе шардирования Vitess. После этого мы опишем решение и пройдемся по всем этапам его реализации.
Распределение по рабочим пространствам
Чтобы понять суть проблем, которые мы хотели решить рефакторингом, нужно описать способ распределения данных по базам MySQL. Изначально большинство данных было распределено по рабочим пространствам. Каждое из них было выделено для одного клиента компании Slack. Я немного рассказывала об этом ранее в разделе «Архитектура Slack 101» главы 10. Распределение данных клиентов по разным шардам было показано на рис. 10.3.
Несколько лет это работало нормально, но постепенно такая схема становилась более неудобной. Это происходило по двум причинам.
Во-первых, усложнялась поддержка операций для самых больших шардов. Шарды, выделенные крупнейшим и наиболее быстрорастущим клиентам, часто страдали от проблем с доступом. Данные таких клиентов, уже занимавшие изолированные шарды, быстро разрастались настолько, что требовалось обновление аппаратного обеспечения, которое мы сделать не могли. Простых механизмов разделения данных по горизонтали у нас не было, и мы не знали, что делать.
Во-вторых, в мессенджер вносились важные изменения для разрушения барьеров между рабочими пространствами, которые долго поддерживались способами написания кода и структурированием данных. Но в какой-то момент был создан функционал, позволивший крупнейшим клиентам объединить несколько рабочих пространств, а двум клиентам напрямую общаться в общем канале.
Несоответствие между тем, как компания видела будущее продукта и способом построения систем вело к усложнению приложения. Это пример деградации кода из-за изменения требований к продукту (глава 2). Проблему наглядно иллюстрирует тот факт, что за год до рефакторинга для успешного определения местоположения канала и его участников приходилось делать запрос к трем шардам. Разработчикам приходилось запоминать правильный набор шагов для извлечения связанных с каналом данных и управления ими.
Чтобы разобраться с операционными проблемами с MySQL и сложностями масштабирования, мы начали оценивать другие варианты хранения. Выбор пал на Vitess (https://vitess.io/) — систему кластеризации баз данных, созданную YouTube, которая обеспечивает горизонтальное масштабирование MySQL. Миграция на Vitess позволит нам делить данные на шарды не только по рабочим пространствам. Так мы сможем освободить место в самых загруженных шардах и распределить данные так, чтобы упростить запросы!
Миграция таблицы channels_members на Vitess
Учитывая эти обстоятельства, мы решили перенести таблицу channels_members в систему Vitess. Это была одна из таблиц с наибольшим трафиком. Изменение способа ее шардирования освобождало много места и уменьшало нагрузку на самые загруженные шарды рабочего пространства. Миграция сильно упрощала логическую схему получения членства в каналах за пределами рабочей области.
Проект был инициирован командой разработчиков инфраструктуры Vitess с помощью инженеров по продукту, хорошо разбиравшихся в шаблонах запросов к таблице channels_members. Это было выигрышное сочетание.
Разработчики инфраструктуры досконально знали систему баз данных. Это позволяло предотвратить ошибки миграции и эффективно решать проблемы с базой данных по мере их возникновения. Тогда они обладали самым большим опытом в области миграции таблиц и лучше всего подходили для руководства проектом. Возглавляла эту группу Мэгги. Инженеры по продукту, включая меня, могли предоставить информацию о новой схеме и схеме шардирования. Нашей задачей была помощь с переписыванием логики приложения под новые варианты запросов.
Мы создали канал #feat-vitess-channels для обмена идеями и координации рабочих потоков. Разослали приглашения присоединиться к нему и сразу приступили к решению первой задачи.
Схема шардирования
Прежде чем переносить в Vitess данные о членстве в каналах, нужно было решить, как они будут распределяться (какие ключи использовать для изменения шардирования таблицы). У нас было два варианта:
— по каналу (channel_id), чтобы запрос к одному шарду давал всю информацию об участниках канала;
— по пользователю (user_id), чтобы запрос к одному шарду давал всю информацию о членстве пользователя.
Поскольку консолидация таблиц завершилась недавно, я помнила, что большинство запросов касались получения членства для данного канала, а не для данного пользователя. Многие из них имели решающее значение для приложения, обеспечивая поиск и возможность упоминания всех участников канала (@channel или here).
Тогда (и по сей день) мы регистрировали образцы всех запросов к базе данных в хранилище данных, чтобы отслеживать использование MySQL при обращениях к нашим производственным системам. Для подтверждения своего предположения, что большая часть обращений к таблице channels_members связана с ключом channel_id, я посмотрела выборку связанных с членством запросов за месяц и передала результат (рис. 11.1) команде.

Но один из сотрудничавших с нами инженеров по продукту, имеющий больший опыт работы с Vitess, указал, что будет лучше провести шардирование по пользователям. В том же самом журнале он показал нам десять самых частых запросов к таблице, отфильтрованных по channel_id (рис. 11.2). Для обеспечения эффективной работы приложения нужно было предусмотреть это поведение.
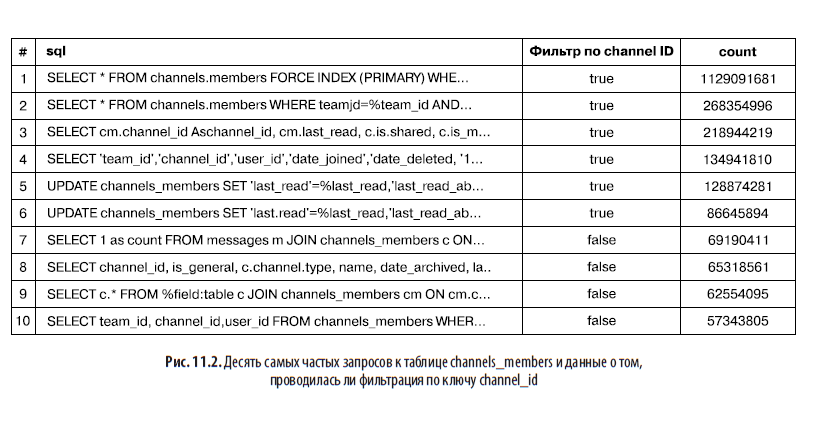
Мы подсчитали примерный объем запросов к базе данных, необходимый для поддержки любого из этих вариантов. Было решено пойти на компромисс, прибегнув к денормализации данных о членстве. В итоге появилось две таблицы: одна шардированная по пользователям, другая — по каналам плюс двойная запись для обоих вариантов. Так точечные запросы получатся дешевыми в обоих случаях.
Разработка новой схемы
Дальше нужно было внимательно взглянуть на существующую схему таблицы, шардированной по рабочим пространствам, и определить, как мы будем ее преобразовывать для получения шардирования по пользователям и каналам. Конечно, можно было бы просто воспользоваться существующей схемой. Но рефакторинг дал нам уникальную возможность пересмотреть некоторые решения. Мы подробнее рассмотрим обе новые схемы, начав с шарда для пользователей. В примере 11.1 мы видим схему шардов по рабочим пространствам, которая применялась до миграции.
Пример 11.1. Оператор CREATE TABLE показывает таблицу channels_members, шардированную по рабочим пространствам
CREATE TABLE `channels_members` (
`user_id` bigint(20) unsigned NOT NULL,
`channel_id` bigint(20) unsigned NOT NULL,
`team_id` bigint(20) unsigned NOT NULL,
`date_joined` int(10) unsigned NOT NULL,
`date_deleted` int(10) unsigned NOT NULL,
`last_read` bigint(20) unsigned NOT NULL,
...
`channel_type` tinyint(3) unsigned NOT NULL,
`channel_privacy_type` tinyint(4) unsigned NOT NULL,
...
`user_team_id` bigint(20) unsigned NOT NULL,
PRIMARY KEY (`user_id`,`channel_id`)
)
Таблица членства, шардированная по пользователям
В случае шардирования по пользователям мы решили сохранить большую часть исходной схемы. Серьезные изменения были внесены только в способ хранения идентификаторов пользователей. Чтобы вам стали понятны мотивы такого решения, расскажу о двух типах идентификаторов пользователей и о том, откуда они взялись.
В начале главы я кратко упомянула, что мы пытались упростить использование мессенджера Slack для крупных клиентов, у которых разным отделам выделялись разные рабочие пространства. Это затрудняло взаимодействие между сотрудниками из разных отделов и управление отдельными рабочими пространствами. Поэтому мы позволили самым крупным клиентам объединить свои многочисленные рабочие пространства.
Но для корректной группировки требовался способ синхронизации пользователей. Давайте посмотрим, как это работало, на простом примере.
В корпорации Acme Corp. для каждого отдела выделено свое рабочее пространство. Одно из них — для команды инженеров и отдела обслуживания клиентов. У каждого сотрудника Acme Corp. есть учетная запись пользователя от организации в целом. Инженеры имеют членство в рабочем пространстве Engineering для общения с товарищами по команде и в Customer Experience (служба поддержки).
Но с точки зрения внутренней структуры то, что выглядит как одна учетная запись Acme Corp., на самом деле — несколько учетных записей. На уровне организации каждый пользователь имеет канонический идентификатор. Одновременно ему сопоставлены несколько локальных для всех рабочих пространств, где он подписан на каналы. Например, у члена рабочих пространств Engineering и Customer Experience три уникальных идентификатора пользователя. Их количество рассчитывается по формуле n + 1, где n — число доступных пользователю рабочих пространств.
Несложно догадаться, что такая система быстро стала очень сложной и благоприятствующей появлению ошибок. Поэтому через год появился план замены всех локальных идентификаторов пользователей каноническими.
Поскольку большинство хранящихся в системах Slack данных связано с определенным идентификатором пользователя (создание сообщения, загрузка файла и прочее), корректно (и по возможности незаметно) перезаписать эти идентификаторы было непросто.
При шардировании по рабочему пространству в таблице channels_members локальные идентификаторы пользователей хранились в столбце user_id. Проект по замене всех локальных идентификаторов каноническими уже стартовал. Мы решили работать совместно с ними и проследить за сохранением во все столбцы идентификаторов канонических user ID.
Комментарии: 0
Пока нет комментариев