



Новости

26.07.2023
Книга «Грокаем глубокое обучение с подкреплением»
Подходы к поиску решений в средах MAB
Есть три основных подхода к поиску решений в MAB. Самый популярный и простой из них основан на исследовании через внедрение элемента случайности в процесс выбора действий: агент будет в основном использовать имеющиеся знания, но иногда исследовать среду случайным путем. Это семейство методов называется случайными стратегиями исследования. Элементарный пример: стратегия, которая большую часть времени выбирает жадное действие, но по достижении порога эпсилон делает равномерно случайный выбор. В связи с этим у нас появляется много вопросов. Например, должно ли значение эпсилон быть одинаковым для всех эпизодов? Нужно ли максимизировать исследование на ранних этапах? Стоит ли периодически увеличивать значение эпсилон, чтобы агент всегда занимался исследованием?
Другой подход к разрешению дилеммы исследования и эксплуатации — это оптимизм. Именно так. Семейство оптимистических стратегий исследования дает нам более систематизированный подход, который количественно характеризует неопределенность в задачах принятия решений и отдает предпочтение наиболее неопределенным состояниям. Суть в том, что оптимизм подталкивает агент к выбору неопределенных состояний: он предполагает, что незнакомые ему состояния должны быть самыми выгодными. Это помогает агенту исследовать среду, и, по мере того как он сталкивается с реальностью, его ожидания становятся все ниже и ниже, приближаясь к реальным показателям.
Третий подход — внедрение семейства стратегий исследования информационного пространства состояний. Они моделируют информацию о состоянии агента в рамках среды. Благодаря внедрению неопределенности в пространство агент будет по-разному воспринимать исследованные и неисследованные состояния. Это действенный метод, но он может существенно увеличить пространство состояний, что усложнит выполнение задачи.
Здесь мы рассмотрим примеры из первых двух подходов. Мы сделаем это на нескольких разных средах MAB с разными свойствами, преимуществами и недостатками. Это позволит нам провести глубокое сравнение нескольких стратегий.
Важно отметить, что в средах MAB оценка Q-функции выглядит довольно просто — это относится ко всем рассматриваемым стратегиям.
Среды MAB одношаговые, поэтому для оценки Q-функции нужно вычислить среднюю награду для каждого действия. Проще говоря, ценность действия a равна общей награде при выборе этого действия, разделенной на количество случаев, в которых оно было выбрано.
Заметьте, что все стратегии, которые мы здесь рассмотрим, оценивают Q-функцию совершенно одинаково. Единственное отличие в том, как каждая из стратегий использует полученное значение для выбора действий.
Конкретный пример
«Скользкая бандитская походка» (СБП) возвращается!
Для начала возьмем уже знакомую нам среду MAB: «скользкая бандитская походка» (СБП)

Как вы помните, СБП — это среда в виде сетки с одной строкой, поэтому мы называем ее «походкой». Но у этой «походки» есть одна особенность: агент начинает посредине и любое действие отправляет его прямиком в конечное состояние. У этой среды один временной шаг, поэтому она «бандитская».
СБП — это «двурукий бандит», который может предстать перед агентом в виде «двурукого бандита Бернулли». «Бандиты Бернулли» выплачивают награду +1 с вероятностью p и нулевую — с вероятностью q = 1 – p. Иначе говоря, сигнал вознаграждения — это распределение Бернулли.
В СБП есть два конечных состояния, одно из которых дает +1, а другое — 0. Если посчитать, можно заметить, что вероятность награды +1 при выборе действия 0 равна 0,2, а при выборе действия 1 — 0,8. Но ваш агент об этом не знает, и мы не станем делиться с ним этой информацией. Нам нужно получить ответы на следующие вопросы: «Насколько быстро наш агент может определить оптимальное действие?», «Сколько всего потерь он накопит, обучаясь максимизировать ожидаемую награду?». Давайте посмотрим.
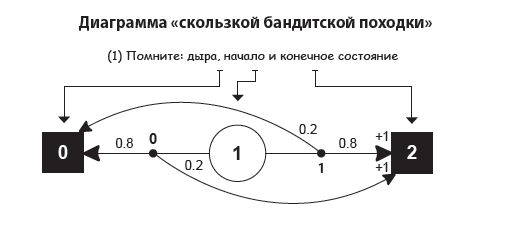
Жадная стратегия: всегда эксплуатировать
Первая стратегия, которую мы рассмотрим, не совсем полноценная: это скорее базовый план. Я уже упоминал, что нам нужно исследовать наши алгоритмы, иначе мы рискуем перейти к неподходящим действиям. Поэтому для сравнения обсудим алгоритм, который вообще не занимается исследованием новой информации.
Этот базовый подход называется жадной стратегией или стратегией чистой эксплуатации. Его суть в том, что мы всегда выбираем действие с наивысшей ожидаемой ценностью. И хотя может случиться так, что первое же выбранное нами действие окажется лучшим, вероятность этого счастливого стечения обстоятельств уменьшается по мере увеличения числа доступных действий.
Как и ожидалось, жадная политика сразу же останавливается на первом действии. Если инициализировать Q-таблицу нулями и если в среде нет отрицательных наград, жадная политика всегда будет выбирать первое действие.
Я знаю Python
Стратегия чистой эксплуатации

Я хочу обратить ваше внимание на связь между жадной стратегией и временем. Если у вашего агента остается всего один эпизод, жадное поведение — лучший выбор. Зная, что это ваш последний день на земле, вы посвятите его вещам, которые приносят вам больше всего положительных эмоций. В этом в какой-то степени суть жадной политики: агент пытается извлечь максимум с учетом ограниченного количества времени и знаний о среде.
Это вполне разумно, когда у вас осталось мало времени. Не сделать этого было бы недальновидно, ведь вы не пожертвуете немедленным удовлетворением или вознаграждением ради информации, которая позволит вам улучшить долгосрочные результаты.
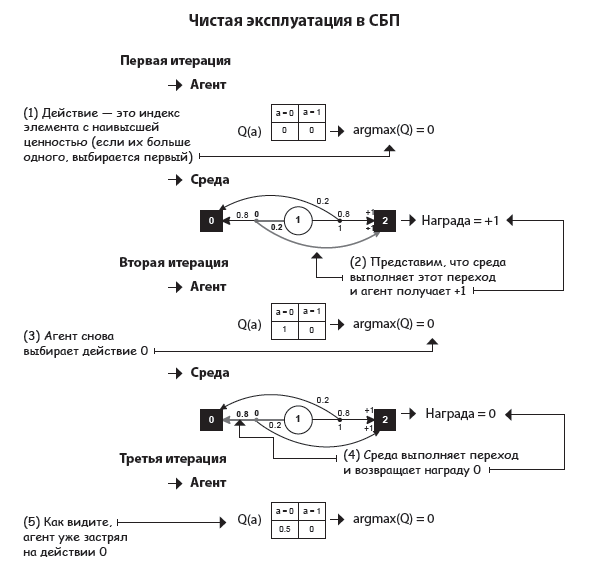
Случайная стратегия: всегда исследуем
Рассмотрим противоположный подход: стратегию, которая занимается только исследованием, но никогда не использует полученную информацию. Это еще один базовый метод, который называется случайной стратегией или стратегией случайного исследования. Это просто процесс выбора действий, который совершенно не предусматривает использования имеющихся знаний. Агент заинтересован только в исследовании.
У вас наверняка есть знакомые, которые перед началом нового проекта тратят много времени на подготовку и никогда не принимают поспешных решений? У меня тоже! Они могут провести целые недели за чтением документации. Этап исследования очень важен, но для получения максимальной выгоды он должен быть сбалансирован.
Очевидно, что случайная стратегия тоже далека от идеала и оптимальных результатов она не даст. Нельзя концентрироваться только на исследовании нового или использовании имеющейся информации. Нам нужен алгоритм, который умеет сочетать эти две стадии.
Я знаю Python
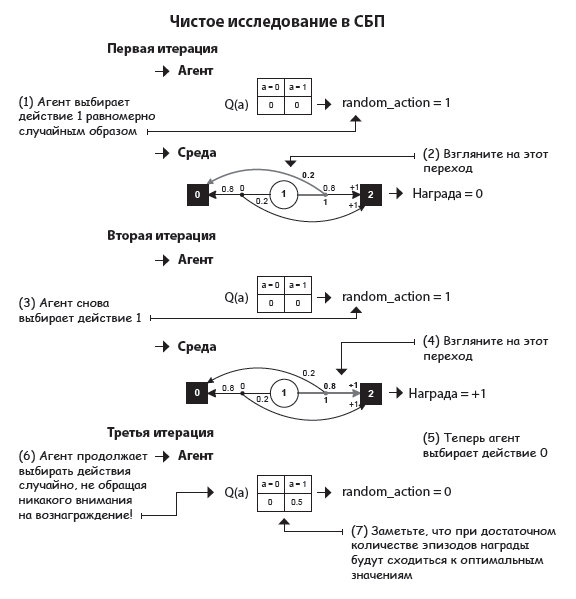
Стратегия чистого исследования

В коде приводится одно замечание, на котором я бы хотел остановиться подробней. Представленная здесь стратегия — лишь один из подходов к исследованию (а именно, случайный). У нее есть много альтернатив. Например, мы можем подсчитывать, сколько раз было выбрано одно действие по сравнению с другими, или сравнивать полученные награды.
Задумайтесь на секунду: использовать информацию можно только одним способом, но исследовать ее можно по-разному. Этап эксплуатации — это не что иное, как выбор действий, которые вы считаете лучшими. Это довольно просто: если вам кажется, что лучше A ничего нет, вы выбираете A.
Этап же исследования намного сложнее. Очевидно, что вам нужно собирать информацию, но как это делать — уже другой вопрос. Вы можете попытаться подтвердить или опровергнуть ваши текущие знания. В основе исследования может лежать как уверенность, так и неопределенность. Список можно продолжать очень долго.
В целом все логично: ваша цель — использование информации, полученной на этапе исследования. Для ее достижения нужно обзавестись знаниями, это понятно. Но получать их можно по-разному, и именно в этом вся сложность.
Эпсилон-жадная стратегия: почти всегда жадная, но иногда случайная
Объединим две базовые стратегии (чистая эксплуатация и чистое исследование), чтобы наш агент мог и собирать информацию, и использовать ее для принятия обоснованных решений. Гибридная стратегия большую часть времени действует жадно, но иногда занимается случайным исследованием.
Такой подход называется эпсилон-жадной стратегией, и работает он на удивление хорошо. Почти всегда выбирая действия, которые кажутся вам лучшими, вы получите хорошие результаты, а это «почти» позволяет исследовать неопробованные варианты. Так ваша функция ценности действий получит возможность сойтись на своем реальном значении, что поможет вам получить больше наград в долгосрочной перспективе.
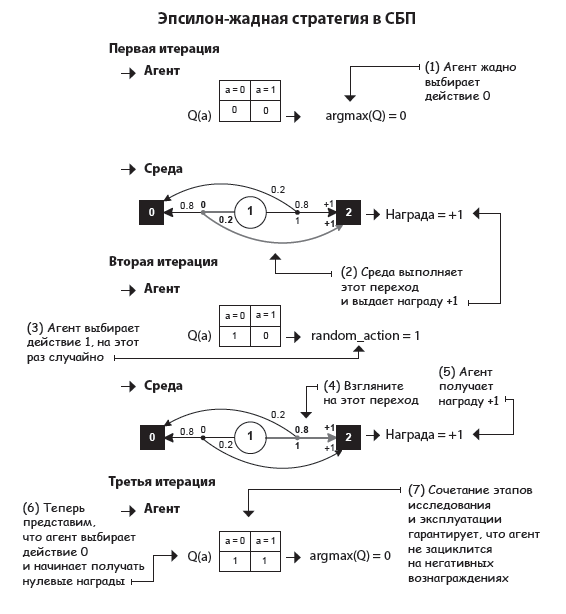
Я знаю Python
Эпсилон-жадная стратегия

Эпсилон-жадная относится к случайным стратегиям исследования, так как при выборе действий используется элемент непредсказуемости. Решение использовать имеющуюся информацию или исследовать новую тоже принимается случайно. Есть и другие виды случайных стратегий исследования: например, функция softmax (о ней мы поговорим немного позже), которая лишена первого этапа случайного принятия решений.
Обратите внимание: если эпсилон равна 0,5 и у вас есть два действия, невозможно сказать, что ваш агент будет заниматься исследованием в 50 % случаев, если под исследованием мы имеем в виду выбор нежадного действия. Также заметьте, что этап исследования в эпсилон-жадной стратегии включает в себя жадное действие. На практике ваш агент будет заниматься исследованием с вероятностью чуть ниже эпсилон, зависящей от количества действий.
Затухающая эпсилон-жадная стратегия: сначала максимизируются исследования, затем эксплуатация
Самые активные исследования логично проводить в начале, когда агент еще недостаточно знаком со средой, а позже, когда у нас уже есть хорошая аппроксимация функции ценности, можно позволить ему чаще использовать полученные знания. Все просто: мы начинаем с большого (меньше или равного 1) значения эпсилон и уменьшаем его с каждым шагом. Такой подход называется затухающей эпсилон-жадной стратегией и может принимать разные формы в зависимости от того, как изменяется значение эпсилон. Ниже я покажу вам два примера.
Я знаю Python
Линейно затухающая эпсилон-жадная стратегия

Я знаю Python
Экспоненциально затухающая эпсилон-жадная стратегия

Есть много других способов применения затухания эпсилона: от простого 1/episode до затухающих синусоидальных волн. Есть даже разные реализации одних и тех же линейных и экспоненциальных методов. Суть в том, что вначале агент с более высокой вероятностью должен заниматься исследованием, а позже нужно ввести возможность применять полученную информацию. На ранних этапах высок риск получения неверных оценочных значений. Но со временем агент узнает больше информации, приближая эти значения к реальности, а это значит, что можно начать меньше заниматься исследованием и больше эксплуатацией.
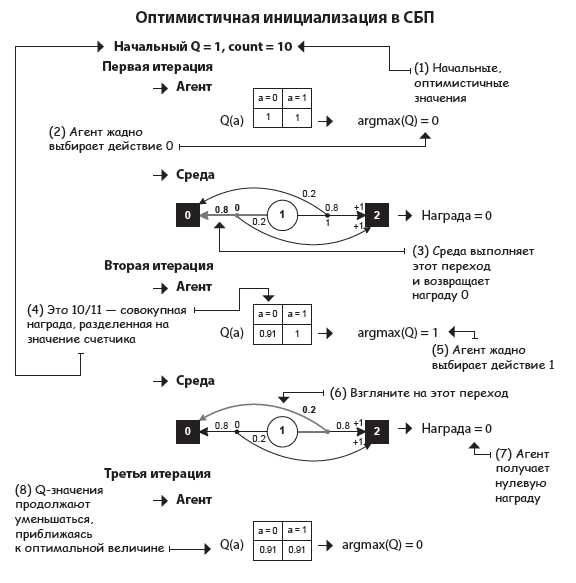
Оптимистичная инициализация: начинаем с веры в то, что все замечательно
Еще один интересный подход к дилемме исследования и эксплуатации: считать недостаточно исследованные действия лучшими из возможных. Этот класс стратегий называется оптимизмом в условиях неопределенности. Одна из его разновидностей — оптимистичная стратегия инициализации.
Принцип ее работы прост: мы изначально присваиваем Q-функции высокую ценность и, исходя из этого значения, ведем себя жадно. Нужно прояснить два момента. Во-первых, высокая ценность — это то, к чему у нас нет доступа в RL. Мы вернемся к этому чуть позже, а пока что притворимся, что это число у нас уже есть. Во-вторых, вместе с Q-значениями нам нужно определить счетчики, используя значение больше 1. Если этого не сделать, Q-функция будет меняться слишком быстро, что снизит эффективность стратегии.
Я знаю Python
Оптимистичная стратегия инициализации

Интересно, правда? Поскольку агент изначально рассчитывает получить больше вознаграждения, чем может получить на самом деле, он исследует среду, пока не найдет источники вознаграждения. С увеличением опыта агент становится менее «наивным»: Q-значения уменьшаются, пока не сойдутся на реальных показателях вознаграждения.
Опять же, инициализируя Q-функцию высоким значением, мы поощряем исследование неопробованных действий. По мере того как агент взаимодействует со средой, наши значения становятся все более низкими и точными, позволяя ему находить и выбирать действия с действительно наивысшей выгодой.
Суть вот в чем: если вы собираетесь быть жадными, то хотя бы проявите оптимизм.
Конкретный пример
Среда «двурукий бандит Бернулли»
Давайте сравним конкретные реализации стратегий выше на примере нескольких сред вида «двурукий бандит Бернулли».
Среда «двурукий бандит Бернулли» содержит единственное неконечное состояние и два действия. Действие 0 получает награды +1 и 0 с вероятностью α и 1 – α соответственно. Действие 1 получает награды +1 и 0 с вероятностью β и 1 – β соответственно.
Это чем-то напоминает СБП. Среде СБП характерны дополняющие друг друга вероятности: действие 0 дает +1 с вероятностью α, а действие 1 дает +1 с вероятностью 1 – α. В этой же, «бандитской» среде вероятности независимы и могут даже быть равными.
Ниже представлена диаграмма MDP для «двурукого бандита Бернулли».
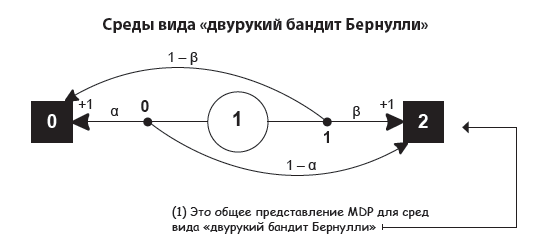
Очень важно понимать, что эту среду можно представить по-разному. На самом деле в коде я ее реализовал иначе, избавившись от большого количества шума.
Взгляните, к примеру, на два конечных состояния: у одного из них может быть два действия с переходом в себя, но если изобразить это на диаграмме, она станет слишком запутанной.
Из всего этого можно извлечь ценный урок: никто вам не запрещает создавать и представлять среды так, как вам удобно. Здесь нет какого-то единого правильного ответа. Конечно, неправильных методов тоже хватает. Поэтому их и нужно исследовать!
Простите, не удержался.
Посчитаем
Простые стратегии исследования в средах вида «двурукий бандит Бернулли»
Я запустил по два экземпляра гиперпараметров всех представленных до сих пор стратегий: эпсилон-жадной, двух затухающих и оптимистичной, а еще базовых методов с чистыми эксплуатацией/исследованием в пяти средах вида «двурукий бандит Бернулли» с вероятностями α и β, инициализированными равномерно случайно, и пятью начальными значениями. Ниже представлены средние результаты после 25 прогонов.

Лучшие результаты в этом эксперименте показала оптимистичная стратегия с начальными Q-значениями 1,0 и десятью первичными расчетами. Производительность остальных тоже оказалась довольно неплохой, несмотря на то что они не были тщательно оптимизированы, так что это все было просто для развлечения — ничего более. Можете открыть блокнот Jupyter для главы 4 и вдоволь поэкспериментировать.
В деталях
Простые стратегии в средах вида «двурукий бандит Бернулли»
Давайте обсудим детали этого эксперимента.
Во-первых, для генерации пяти разных сред вида «двурукий бандит Бернулли» я использовал пять разных начальных значений (12, 34, 56, 78, 90). Помните: все «бандиты Бернулли» возвращают награду +1 с определенной вероятностью, которая своя у каждой руки.
Ниже перечислены полученные среды и вероятность выгоды в них:
- «двурукий бандит» с начальным значением 12. Вероятность награды: [0,41630234; 0,5545003];
- «двурукий бандит» с начальным значением 34. Вероятность награды: [0,88039337; 0,56881791];
- «двурукий бандит» с начальным значением 56. Вероятность награды: [0,44859284; 0,9499771];
- «двурукий бандит» с начальным значением 78. Вероятность награды: [0,53235706; 0,84511988];
- «двурукий бандит» с начальным значением 90. Вероятность награды: [0,56461729; 0,91744039].
Средняя оптимальная величина этих значений — 0,83.
Все эти стратегии были применены в каждой из перечисленных выше сред с пятью разными начальными значениями (12, 34, 56, 78, 90), чтобы смягчить перепады между результатами и исключить из них фактор случайности. Первым я использовал начальное значение 12 для создания «бандита Бернулли», затем с помощью значений 12, 34 и т.д. я измерил производительность каждой стратегии в среде, созданной с начальным значением 12.
После я создал еще одного «бандита Бернулли» с использованием начального значения 34 и затем оценил в его рамках каждую стратегию, применяя значения 12, 34 и т.д. В итоге я получил средние показатели для пяти сред и пяти начальных значений, что дало 25 разных прогонов для каждой среды.
Я оптимизировал каждую стратегию по отдельности вручную: из примерно десяти комбинаций гиперпараметров я выбрал две лучшие.
Стратегическое исследование
Представьте, что вам нужно написать агент RL, который будет учиться водить автомобиль. Для этого вы решили реализовать эпсилон-жадную стратегию исследования. Вы загрузили свой агент в бортовой компьютер, повернули ключ зажигания, нажали красивую зеленую кнопку, и ваша машина начала свое исследование. Она подбрасывает воображаемую монету и выбирает случайное действие, скажем движение по противоположной стороне дороги. Нравится вам такое? Мне тоже нет. Надеюсь, этот пример помог показать важность выбора разных стратегий исследования.
Конечно, я немного преувеличил. Никто не позволил бы необученному агенту познавать реальный окружающий мир напрямую. На практике, прежде чем применить RL в настоящих автомобилях, беспилотных аппаратах и т.п., агент сначала проходит предварительное обучение в симуляции и/или использует более эффективные методы выборки.
Но то, о чем я говорил выше, по-прежнему верно. Если подумать, то мы, люди, не познаем окружающий мир случайно. Ну, кроме младенцев. Возможно, неопределенность и вносит в нашу жизнь некоторый элемент случайности, но мы, к примеру, не женимся на первом встречном без причины (если это не Лас-Вегас, конечно). Я бы сказал, что взрослые подходят к процессу исследования более стратегически. Мы понимаем, что для получения долгосрочного удовлетворения приходится жертвовать краткосрочным, и осознанно пытаемся получить информацию. Мы познаем окружающий мир, пробуя то неизведанное, которое может потенциально улучшить нашу жизнь. Возможно, наши стратегии исследования — это сочетание оценок со степенью их неопределенности. Например, вместо любимого блюда, которое мы заказываем каждые выходные, мы можем предпочесть то, которое нам, скорее всего, понравится. Быть может, мы исследуем, основываясь на нашей любознательности или погрешности наших предсказаний. Например, заказав в ресторане интересное блюдо, которое мы еще не пробовали, мы можем неожиданно открыть для себя то, что до этого мы не ели ничего вкуснее. «Погрешность предсказаний» и такой «сюрприз» могут иногда служить стимулами для исследования окружающей среды.
Оставшаяся часть этой главы посвящена более развитым стратегиям исследования. Несколько из них тоже используют элемент случайности, но делают это пропорционально текущим оценкам действий, а некоторые учитывают степень уверенности и неопределенности в этих оценках.
С учетом вышесказанного я еще раз хочу подчеркнуть, что эпсилон-жадная стратегия исследования (и ее затухающие версии) по-прежнему самая популярная: возможно, из-за хорошей производительности, а возможно, из-за ее простоты. Может быть, дело в том, что большинство сред обучения с подкреплением на сегодняшний день существуют только внутри компьютера, а в виртуальном мире вопрос человеческой безопасности стоит не так остро. Подумайте над этим хорошенько. Поиск баланса между исследованием (сбором) новой информации и использованием уже имеющейся — базовый аспект человеческого и искусственного интеллекта, равно как и обучения с подкреплением. Я уверен, что прогресс в этом направлении сильно повлияет на искусственный интеллект, обучение с подкреплением и на все другие области, заинтересованные в этом фундаментальном компромиссе.
Более подробно с книгой можно ознакомиться на сайте издательства.
Комментарии: 0
Пока нет комментариев