


Новости

13.09.2020
Книга «Google BigQuery. Всё о хранилищах данных, аналитике и машинном обучении»
Вальяппа Лакшманан и Джордан Тайджани научат вас работать в современном хранилище данных, используя все возможности масштабируемого, безсерверного публичного облака. С этой книгой вы: — Погрузитесь во внутреннее устройство BigQuery — Изучите типы данных, функции и операторы, которые поддерживает Big Query — Оптимизируете запросы и реализуете схемы повышения производительности или снижения затрат — Узнаете о GIS, time travel, DDL / DML, пользовательских функциях и сценариях SQL — Решите множество задач машинного обучения — Узнаете, как защитить данные, отслеживать работу и авторизовать пользователей.
Минимизация сетевых издержек
Минимизация сетевых издержек BigQuery — это региональный сервис, доступный по всему миру. Например, если вы запрашиваете набор данных, хранящийся в регионе EU, запрос будет выполняться на серверах, расположенных в вычислительном центре в Евросоюзе. Чтобы вы могли сохранить результаты запроса в таблице, она должна находиться в наборе данных, который также находится в регионе EU. Однако BigQuery REST API можно вызывать (то есть запустить запрос) из любой точки мира, даже с компьютеров за пределами GCP. При работе с другими ресурсами GCP, такими как Google Cloud Storage или Cloud Pub/Sub, наилучшая производительность достигается, если они находятся в том же регионе, что и набор данных. Поэтому если запрос выполняется из экземпляра Compute Engine или кластера Cloud Dataproc, сетевые издержки окажутся минимальными, если экземпляр или кластер также находятся в том же регионе, что и запрашиваемый набор данных. Обращаясь к BigQuery из-за пределов GCP, учитывайте топологию сети и постарайтесь свести к минимуму число переходов между клиентским компьютером и вычислительным центром GCP, в котором находится набор данных.
Сжатые, неполные ответы
При непосредственном обращении к REST API сетевые издержки можно уменьшить, принимая сжатые, неполные ответы. Для приема сжатых ответов можете указать в HTTP-заголовке, что вы готовы принять gzip-архив, и обеспечить наличие строки «gzip» в заголовке User-Agent, например:

В этом случае все ответы будут сжиматься с помощью gzip. По умолчанию ответы BigQuery содержат все поля, перечисленные в документации. Однако если известно, какая часть ответа нам интересна, мы можем попросить BigQuery послать только эту часть, уменьшив тем самым сетевые издержки. Например, в этой главе мы видели, как получить полную информацию о задании с помощью Jobs API. Если вас интересует только подмножество полного ответа (например, только шаги в плане запроса), можно указать интересующие поля, чтобы ограничить размер ответа:
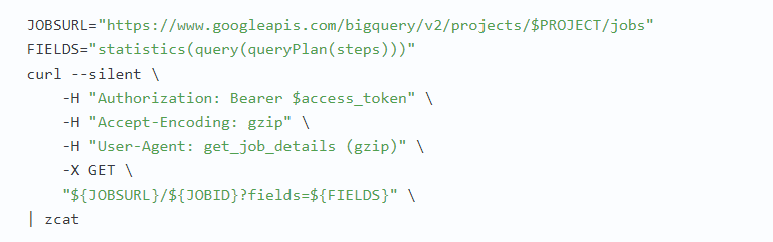
Обратите внимание: здесь также указано, что мы принимаем сжатые данные gzip.
Объединение нескольких запросов в пакеты
При использовании REST API есть возможность объединить несколько вызовов BigQuery API, используя тип содержимого multipart/mixed и вложенные HTTP-запросы в каждой из частей. В теле каждой части указывается HTTP-операция (GET, PUT и т. д.), путь в URL, заголовки и тело. В ответ сервер отправит единственный HTTP-ответ с типом содержимого multipart/mixed, каждая часть которого будет содержать ответ (по порядку) на соответствующий запрос в пакетном запросе. Несмотря на то что ответы возвращаются в определенном порядке, сервер может обрабатывать вызовы в любом порядке. Поэтому пакетный запрос можно рассматривать как группу запросов, выполняемых параллельно. Вот пример отправки пакетного запроса для получения некоторых деталей из планов выполнения последних пяти запросов в нашем проекте. Сначала мы используем инструмент командной строки BigQuery, чтобы получить пять последних успешных заданий:

Запрос отправляется в конечную точку BigQuery, предназначенную для обработки пакетов:

В пути URL можно определить отдельные запросы:
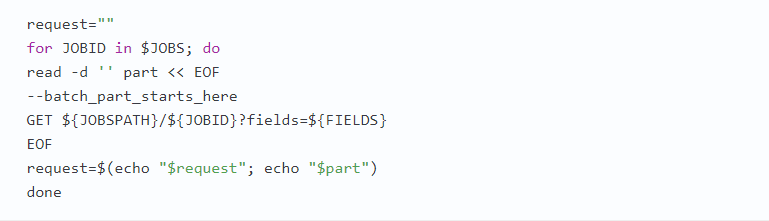
Затем можно отправить запрос в виде составного запроса:

Массовое считывание с использованием BigQuery Storage API
В главе 5 мы обсудили использование BigQuery REST API и клиентских библиотек для перечисления таблиц и получения результатов запросов. REST API возвращает данные в виде записей с разбивкой по страницам, которые лучше подходят для относительно небольших наборов результатов. Однако с появлением машинного обучения и распределенных инструментов извлечения, преобразования и загрузки (Extract, Transform, Load — ETL) теперь внешним инструментам требуется быстрый и эффективный массовый доступ к управляемому хранилищу BigQuery. Такой доступ к массовому чтению обеспечивается в BigQuery Storage API через протокол вызова удаленных процедур (Remote Procedure Call, RPC). С помощью BigQuery Storage API структурированные данные передаются по сети в двоичном формате сериализации, который точнее соответствует колоночному формату хранения данных. Это обеспечивает дополнительное распараллеливание набора результатов между несколькими потребителями.
Конечные пользователи не используют BigQuery Storage API напрямую. Вместо этого они применяют Cloud Dataflow, Cloud Dataproc, TensorFlow, AutoML, и другие инструменты, использующие Storage API для чтения данных напрямую из управляемого хранилища, а не через BigQuery API.
Поскольку Storage API напрямую обращается к хранимым данным, разрешение на доступ к BigQuery Storage API отличается от существующего BigQuery API. Разрешения BigQuery Storage API должны настраиваться независимо от разрешений BigQuery.
BigQuery Storage API предоставляет несколько преимуществ инструментам, читающим данные непосредственно из управляемого хранилища BigQuery. Например, потребители могут читать непересекающиеся наборы записей из таблицы, используя несколько потоков (например, разрешив распределенное чтение данных от разных рабочих серверов в Cloud Dataproc), динамически сегментировать эти потоки (таким способом уменьшая хвостовую задержку, которая может быть серьезной проблемой для заданий MapReduce), выбирать подмножество столбцов для чтения (для передачи в структуры машинного обучения только признаков, используемых моделью), фильтровать значения столбцов (уменьшая объем данных, передаваемых по сети) и при этом гарантировать согласованность мгновенных снимков (то есть читая данные с определенного момента времени).
В главе 5 мы рассмотрели использование расширения %%bigquery в Jupyter Notebook для загрузки результатов запросов в объекты DataFrame. Однако в примерах использовались относительно небольшие наборы данных — от десятка до нескольких сотен записей. А можно ли загрузить весь набор данных london_bicycles (24 миллиона записей) в DataFrame? Да, можно, но в этом случае для загрузки данных в DataFrame следует использовать Storage API, а не BigQuery API. Сначала нужно установить клиентскую библиотеку Storage API для Python с поддержкой Avro и pandas. Сделать это можно командой

Затем остается только использовать расширение %%bigquery, как и прежде, но добавить параметр, требующий использовать Storage API:

Обратите внимание, что здесь мы используем способность Storage API предоставлять прямой доступ к отдельным столбцам; необязательно читать всю таблицу BigQuery в объект DataFrame. Если запрос вернет небольшой объем данных, расширение автоматически будет использовать BigQuery API. Поэтому не страшно, если вы всегда будете указывать этот флаг в ячейках блокнота. Чтобы включить флаг --usebqstorageapi во всех ячейках блокнота, можно установить флаг контекста:

Выбор эффективного формата хранения
Производительность запроса зависит от того, где и в каком формате хранятся данные, составляющие таблицу. В общем случае производительность тем выше, чем меньше запросу требуется выполнять поиск или преобразование типов.
Внутренние и внешние источники данных
BigQuery поддерживает запросы к внешним источникам, таким как Google Cloud Storage, Cloud Bigtable и Google Sheets, однако максимальная производительность запросов возможна только при использовании собственных таблиц.
В качестве хранилища аналитических данных для всех ваших структурированных и полуструктурированных данных мы советуем использовать BigQuery. Внешние источники данных лучше использовать только для промежуточного хранения (Google Cloud Storage), загрузки в режиме реального времени (Cloud Pub/Sub, Cloud Bigtable) или периодического обновления (Cloud SQL, Cloud Spanner). Далее настройте конвейер данных для загрузки данных по расписанию из этих внешних источников в BigQuery (см. главу 4).
Если вам понадобится запросить данные из Google Cloud Storage, по возможности сохраните их в сжатом колоночном формате (например, Parquet). Используйте форматы на основе записей, такие как JSON или CSV, только в крайнем случае.
Управление жизненным циклом промежуточных корзин
Если вы загружаете данные в BigQuery, предварительно помещая в облачное хранилище Google Cloud Storage, не забудьте удалить их из облачного хранилища после загрузки. Если для загрузки данных в BigQuery используется конвейер ETL (чтобы попутно значительно преобразовать их или оставить только часть данных), у вас может появиться желание сохранить исходные данные в Google Cloud Storage. В таких случаях снизить затраты вам поможет определение правил управления жизненным циклом корзин, понижающих класс хранения в Google Cloud Storage.
Вот как можно включить управление жизненным циклом корзины и настроить автоматическое перемещение данных из объединенных регионов или стандартных классов, возраст которых превысил 30 дней, в хранилище Nearline Storage, а данных, хранящихся в Nearline Storage дольше 90 дней, — в хранилище Coldline Storage:

В этом примере файл lifecycle.yaml содержит следующий код:

Вы можете использовать управление жизненным циклом не только для изменения класса объекта, но и для удаления объектов старше определенного порога.
С полным содержанием статьи можно ознакомиться на сайте "Хабрахабр":
Комментарии: 0
Пока нет комментариев