



Новости

14.05.2020
Машинное обучение на R: экспертные техники для прогностического анализа
Книга является руководством, которое поможет применять методы машинного обучения в решении ежедневных задач. Бретт Ланц научит всему необходимому для анализа данных, формирования прогнозов и визуализации данных. Здесь вы найдете информацию о новых улучшенных библиотеках, советы об этических аспектах машинного обучения и проблемах предвзятости, а также познакомитесь с глубоким обучением.
В этой книге — Основы машинного обучения и особенности обучения компьютера на примерах. — Подготовка данных к использованию в машинном обучении средствами языка R. — Классификация значимости результатов. — Предсказание событий с помощью деревьев решений, правил и опорных векторов. — Прогнозирование числовых данных и оценка финансовых данных с помощью регрессионных методов. — Моделирование сложных процессов с использованием нейронных сетей – фундамент глубокого обучения. — Оценка моделей и улучшение их производительности. — Новейшие технологии для обработки больших данных, в частности R 3.6, Spark, H2O и TensorFlow.
Для кого предназначена книга
Книга предназначена для тех, кто рассчитывает использовать данные в конкретной области. Возможно, вы уже немного знакомы с машинным обучением, но никогда не работали с языком R; или, наоборот, немного знаете об R, но почти не знаете о машинном обучении. В любом случае эта книга поможет вам быстро начать работу. Было бы полезно немного освежить в памяти основные понятия математики и программирования, но никакого предварительного опыта не потребуется. Вам нужно лишь желание учиться.
О чем вы прочтете в издании
Глава 1 «Введение в машинное обучение» содержит терминологию и понятия, которые определяют и выделяют теорию машинного обучения среди других областей, а также включает информацию о том, как выбрать алгоритм, подходящий для решения конкретной задачи.
Глава 2 «Управление данными и их интерпретация» даст вам возможность полностью погрузиться в работу с данными в среде R. Здесь речь пойдет об основных структурах данных и процедурах, используемых для загрузки, исследования и интерпретации данных.
Глава 3 «Ленивое обучение: классификация с использованием метода ближайших соседей» научит вас понимать и применять простой, но мощный алгоритм машинного обучения для решения вашей первой практической задачи: выявления особо опасных видов рака.
Глава 4 «Вероятностное обучение: классификация с использованием наивного байесовского классификатора» раскрывает основные понятия теории вероятностей, которые используются в современных системах фильтрации спама. Создавая собственный фильтр спама, вы изучите основы интеллектуального анализа текста.
Глава 5 «Разделяй и властвуй: классификация с использованием деревьев решений и правил» посвящена нескольким обучающим алгоритмам, прогнозы которых не только точны, но и легко интерпретируемы. Мы применим эти методы к задачам, в которых важна прозрачность.
Глава 6 «Прогнозирование числовых данных: регрессионные методы» познакомит с алгоритмами машинного обучения, используемыми для числовых прогнозов. Поскольку эти методы тесно связаны с областью статистики, вы также изучите базовые понятия, необходимые для понимания числовых отношений.
Глава 7 «Методы “черного ящика”: нейронные сети и метод опорных векторов» описывает два сложных, но мощных алгоритма машинного обучения. Их математика на первый взгляд может вас испугать, однако мы разберем примеры, иллюстрирующие их внутреннюю работу.
Глава 8 «Обнаружение закономерностей: анализ потребительской корзины с помощью ассоциативных правил» объясняет алгоритм, используемый в рекомендательных системах, применяемых во многих компаниях розничной торговли. Если вы когда-нибудь задумывались о том, почему системы розничных продаж знают ваши покупательские привычки лучше, чем вы сами, то эта глава раскроет их секреты.
Глава 9 «Поиск групп данных: кластеризация методом k-средних» посвящена процедуре поиска кластеров связанных элементов. Мы воспользуемся этим алгоритмом для идентификации профилей в онлайн-сообществе.
Глава 10 «Оценка эффективности модели» предоставит информацию о том, как измерить успешность проекта машинного обучения и получить надежный прогноз использования конкретного метода в будущем на других данных.
Глава 11 «Повышение эффективности модели» раскрывает методы, используемые теми, кто возглавляет список лидеров в области машинного обучения. Если в вас живет дух соревновательности или вы просто хотите получить максимальную отдачу от своих данных, то вам необходимо добавить эти методы в свой арсенал.
Глава 12 «Специальные разделы машинного обучения» исследует границы машинного обучения: от обработки больших данных до ускорения работы R. Прочитав ее, вы откроете для себя новые горизонты и узнаете, что еще можно делать с помощью R.
Пример: моделирование прочности бетона с помощью нейронной сети
В области инженерно-строительных работ крайне важно иметь точные оценки эффективности строительных материалов. Эти оценки необходимы для разработки правил безопасности, регулирующих использование материалов при строительстве зданий, мостов и дорог.
Особый интерес представляет оценка прочности бетона. Бетон используется практически при любом строительстве, эксплуатационные характеристики бетона сильно различаются, так как он состоит из огромного количества ингредиентов, которые взаимодействуют комплексно. В результате трудно точно сказать, какова будет прочность готового продукта. Модель, которая бы позволяла определить прочность бетона наверняка, с учетом состава исходных материалов, могла бы обеспечить более высокий уровень безопасности строительных объектов.
Шаг 1. Сбор данных
Для этого анализа мы будем использовать данные о прочности бетона на сжатие, переданные Ай-Ченг Йе (I-Cheng Yeh) в репозиторий данных для машинного обучения UCI Machine Learning Repository (http://archive.ics.uci.edu/ml). Поскольку Ай-Ченг Йе успешно использовал нейронные сети для моделирования этих данных, мы попытаемся воспроизвести его работу, применив простую модель нейронной сети в среде R.
Судя по сайту, этот набор данных содержит 1030 записей о разных марках бетона с восемью характеристиками, описывающими компоненты, используемые в составе бетонной смеси. Считается, что эти характеристики влияют на итоговую прочность при сжатии. К ним относятся: количество (в килограммах на кубический метр) цемента, воды, разных добавок, крупных и мелких заполнителей типа щебня и песка, используемых в готовом продукте, а также время схватывания (в днях).
Для того чтобы выполнить этот пример, загрузите файл concrete.csv и сохраните его в рабочем каталоге R.
Шаг 2. Исследование и подготовка данных
Как обычно, начнем анализ с загрузки данных в R-объект с помощью функции read.csv() и убедимся, что результат соответствует ожидаемой структуре:
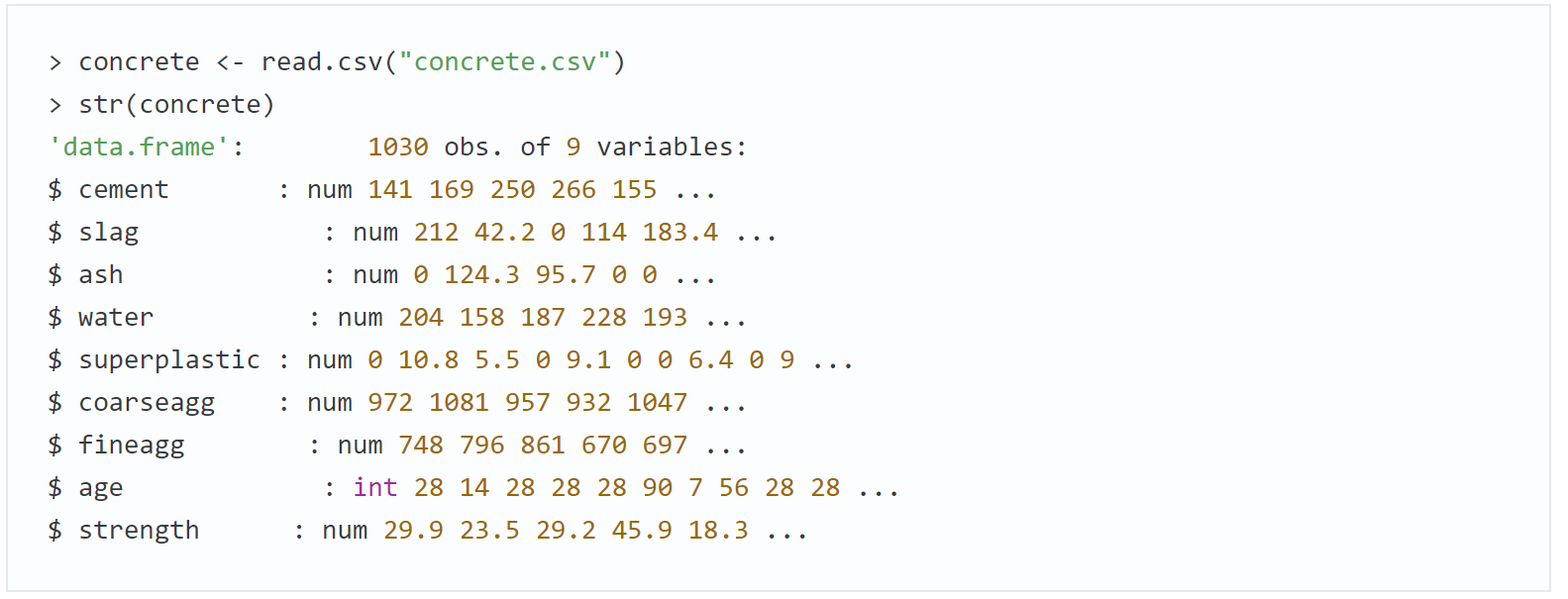
Девять переменных во фрейме данных соответствуют восьми характеристикам и одному ожидаемому результату, но стало очевидно, что есть проблема. Нейронные сети лучше всего работают тогда, когда входные данные масштабируются до узкого диапазона с центром около 0, а здесь мы видим значения в диапазоне от 0 до более чем 1000.
Как правило, решение такой проблемы заключается в изменении масштаба данных с помощью функции нормализации или стандартизации. Если распределение данных соответствует колоколообразной кривой (нормальное распределение, см. главу 2), то, возможно, имеет смысл использовать стандартизацию с помощью встроенной функции scale(). Если же распределение данных близко к равномерному или сильно отличается от нормального, то более подходящей может быть нормализация к диапазону от 0 до 1. В данном случае будем использовать последний вариант.
В главе 3 мы создали собственную функцию normalize():

После того как будет выполнен этот код, можно применить функцию normalize() ко всем столбцам выбранного фрейма данных с помощью функции lapply():
> concrete_norm <- as.data.frame(lapply(concrete, normalize))
Чтобы убедиться, что нормализация сработала, можно проверить, равны ли минимальное и максимальное значения признака strength 0 и 1 соответственно:

Для сравнения: исходные минимальное и максимальное значения этого признака были равны 2.33 и 82.60 соответственно:

Любое преобразование, примененное к данным до обучения модели, впоследствии должно быть применено в обратном порядке, чтобы преобразовать признак назад в исходные единицы измерения. Для облегчения масштабирования целесообразно сохранить исходные данные или хотя бы сводную статистику исходных данных.
Следуя сценарию, описанному Йе в исходной статье, разделим данные на тренировочный набор, включающий в себя 75 % всех примеров, и тестовый набор, состоящий из 25 %. Используемый CSV-файл отсортирован в случайном порядке, поэтому нам остается лишь разделить его на две части:
> concrete_train <- concrete_norm[1:773, ]
> concrete_test <- concrete_norm[774:1030, ]
Мы будем использовать тренировочный набор данных для построения нейронной сети и тестовый набор данных для оценки того, насколько хорошо модель обобщается для будущих результатов. Поскольку нейронную сеть легко довести до состояния переобучения, этот шаг очень важен.
Шаг 3. Обучение модели на данных
Чтобы смоделировать взаимосвязь между ингредиентами, используемыми в производстве бетона, и прочностью готового продукта, построим многослойную нейронную сеть прямого распространения. Пакет neuralnet, разработанный Стефаном Фритчем (Stefan Fritsch) и Фрауке Гюнтер (Frauke Guenther), обеспечивает стандартную и простую в использовании реализацию таких сетей. В этот пакет также входит функция для построения топологии сети. Реализация neuralnet — хороший способ получить дополнительную информацию о нейронных сетях, хотя это не означает, что ее нельзя использовать и для выполнения реальной работы — как вы скоро убедитесь, это довольно мощный инструмент.
В R есть еще несколько пакетов, обычно используемых для обучения моделей нейронных сетей, каждый из которых имеет свои достоинства и недостатки. Поскольку nnet поставляется в составе стандартного комплекта R, он является, пожалуй, наиболее часто упоминаемой реализацией нейронных сетей. В пакете использован немного более сложный алгоритм, чем стандартный метод обратного распространения ошибки. Еще один вариант — пакет RSNNS, содержащий полный набор функций для нейронной сети, но его недостатком является то, что этот пакет труднее освоить.
Поскольку пакет neuralnet не включен в базовый R, вам нужно будет его установить, введя команду install.packages(«neuralnet»), и загрузить с помощью команды library(neuralnet). Входящую в пакет функцию neuralnet() можно применять для обучения нейронных сетей числовому прогнозированию с использованием следующего синтаксиса.
С полным содержанием статьи можно ознакомиться на сайте "Хабрахабр": https://habr.com/ru/company/piter/blog/496256/
Комментарии: 0
Пока нет комментариев