


Новости

28.02.2024
Книга «100 ошибок Go и как их избежать»
Вы научитесь писать идиоматичный и выразительный код на Go, разберете десятки интересных примеров и сценариев и поймете, как обнаружить ошибки и потенциальные ошибки в своих приложениях. Чтобы вам было удобнее работать с книгой, автор разделил методы предотвращения ошибок на несколько категорий, начиная от типов данных и работы со строками и заканчивая конкурентным программированием и тестированием.
Для опытных Go-разработчиков, хорошо знакомых с синтаксисом языка.
5.1. ОШИБКА #36: НЕ ПОНИМАТЬ КОНЦЕПЦИИ РУН
Для начала обсудим концепцию рун в Go. Эта концепция — ключ к пониманию того, как обрабатываются строки, что позволяет избежать распространенных ошибок. Для начала освежим основные понятия.
Важно понимать разницу между кодировкой символов (charset) и кодированием (encoding):
- Кодировка символов, charset, — это просто набор символов. Например, кодировка Unicode содержит 221 символ.
- Кодирование — это перевод списка символов в двоичный код. Например, UTF-8 — это стандарт кодирования, определяющий способ того, как возможно закодировать все символы Unicode в переменном количестве байтов (от 1 до 4 байт).
Мы упомянули слово «символы», чтобы упростить определение кодировки. Но в Unicode мы используем концепцию кодовой точки для ссылки на элемент, представленный одним значением. Например, символ 汉 определяется кодовой точкой U+6C49. Используя UTF-8, 汉 кодируется тремя байтами: 0xE6, 0xB1 и 0x89. Почему это важно? Потому что в Go руна — это кодовая точка Unicode.
Мы сказали, что UTF-8 кодирует символы в количестве байтов от 1 до 4 байт, следовательно, до 32 бит. Вот почему в Go руна — это псевдоним типа int32:
type rune = int32
Еще одна вещь, важная для UTF-8: некоторые считают, что строки Go всегда имеют кодировку UTF-8, но это не так. Рассмотрим пример:
s := "hello"
Мы присваиваем строковый литерал (строковую константу) переменной s. В Go исходный код представлен в UTF-8, то есть все строковые литералы кодируются в последовательность байтов с использованием UTF-8. Но строка представляет собой последовательность произвольных байтов, и она не обязательно основана на UTF-8. Когда мы работаем с переменной, которая не была инициализирована из строкового литерала (например, при чтении из файловой системы), мы не можем считать по умолчанию, что она использует кодировку UTF-8.
ПРИМЕЧАНИЕ
golang.org/x — репозиторий, предоставляющий расширения стандартной библиотеки, — содержит пакеты для работы с UTF-16 и UTF-32.
Вернемся к примеру с приветствием. Есть строка, состоящая из пяти символов: h, e, l, l и o.
Эти простые символы кодируются с использованием одного байта каждый. Вот почему вызов функции запроса длины s возвращает 5:
s := "hello"
fmt.Println(len(s)) // 5
Но символ не всегда кодируется одним байтом. Возвращаясь к символу 汉, мы упомянули, что в UTF-8 он кодируется тремя байтами. Это подтверждается примером:
s := "汉"
fmt.Println(len(s)) // 3
Вместо 1 в этом примере выводится 3. Применяемая к строке встроенная функция len возвращает не количество символов, а число байтов.
И наоборот, мы можем создать строку, отталкиваясь от списка байтов. Мы уже упоминали, что символ 汉 кодируется тремя байтами: 0xE6, 0xB1 и 0x89:
s := string([]byte{0xE6, 0xB1, 0x89})
fmt.Printf("%s\n", s)
Здесь мы создаем строку из этих трех байтов. Когда мы выводим ее, то получаем не три символа, а один: 汉.
Выводы:
- Кодировка символов — это набор символов. Кодирование же описывает, как кодировка преобразовывается в двоичный код.
- В Go строка ссылается на неизменяемый срез произвольных байтов.
- Исходный код Go использует UTF-8. Все строковые литералы — строки UTF-8. Но поскольку строка может содержать какие угодно произвольные байты, если получена откуда-то еще (а не из исходного кода), то нет гарантии, что она будет основана на кодировке UTF-8.
- Руна соответствует понятию кодовой точки Unicode, означающей элемент, представленный одним значением.
- При использовании UTF-8 кодовая точка Unicode может быть закодирована с помощью одного, двух, трех или четырех байтов.
- Применение функции len к строке возвращает количество байтов, а не количество рун.
Знать эти понятия необходимо, потому что руны в Go встречаются повсюду. Посмотрим на конкретное применение этих знаний в связи с распространенной ошибкой, совершаемой при итерации строк.
5.2. ОШИБКА #37: НЕТОЧНАЯ ИТЕРАЦИЯ СТРОК
Итерация строк — распространенное действие. Возможно, мы хотим выполнить какую-то операцию для каждой руны в строке или реализовать пользовательскую функцию для поиска определенной подстроки. В обоих случаях мы должны осуществлять перебор разных рун строки. Но в том, как работает итерация, легко запутаться.
Рассмотрим пример, где хотим вывести разные руны в строке и их соответствующие позиции:
s := "hêllo" Литерал строки содержит специальную руну — ê.
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
Мы используем оператор range для итерации по s, а затем выводим каждую руну, используя ее индекс в строке. Вот результат:
position 0: h
position 1: Ã
position 3: l
position 4: l
position 5: o
len=6
Этот код делает не то, что мы хотим. Выделим три момента:
- Вторая руна в выводе на печать — Ã, а не ê.
- Мы перепрыгнули с позиции 1 сразу на позицию 3… Но что находится на позиции 2?
- len возвращает число 6, тогда как s содержит только 5 рун.
Начнем с последнего момента. Мы уже упоминали, что len возвращает количество байтов в строке, а не количество рун. Поскольку мы присвоили s значение строкового литерала, то s будет строкой UTF-8. При этом специальный символ ê не кодируется одним байтом — для этого требуется два байта. Следовательно, вызов len(s) возвращает 6.
Подсчет количества рун в строке
А что, если мы хотим получить количество рун в строке, а не количество байтов? То, как мы сможем это сделать, будет зависеть от кодировки.
В предыдущем примере мы присвоили s значение строкового литерала, поэтому можно использовать пакет unicode/utf8:
fmt.Println(utf8.RuneCountInString(s)) // 5
Вернемся к рассматриваемому циклу, чтобы понять оставшиеся сюрпризы:
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
Мы должны признать, что в этом примере итерируем не каждую руну, а каждый начальный индекс руны, как показано на рис. 5.1.
При выводе на печать s[i] выводится не i-я руна, а байт с индексом i в представлении UTF-8. Следовательно, мы вывели hÃllo вместо hêllo. Как исправить код, чтобы он выводил все разнообразные руны? Есть два варианта.
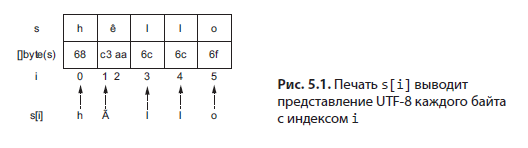
Мы должны использовать значение элемента оператора range:
s := "hêllo"
for i, r := range s {
fmt.Printf("position %d: %c\n", i, r)
}
Чтобы не выводить руну с помощью s[i], мы используем переменную r. Использование цикла range для строки возвращает две переменные: начальный индекс руны и саму руну:
position 0: h
position 1: ê
position 3: l
position 4: l
position 5: o
Другой подход заключается в преобразовании строки в срез рун и итерации по нему:
s := "hêllo"
runes := []rune(s)
for i, r := range runes {
fmt.Printf("position %d: %c\n", i, r)
}
position 0: h
position 1: ê
position 2: l
position 3: l
position 4: o
Здесь мы преобразуем s в срез рун, используя []rune(s). Затем мы проводим итерацию по этому срезу и используем значение элемента оператора range для вывода всех рун. Единственная разница связана с позицией: вместо вывода начального индекса последовательности байтов руны код выводит непосредственно индекс руны.
Это решение приводит к оверхеду на время выполнения по сравнению с предыдущим. Действительно, преобразование строки в срез рун требует выделения места в памяти для дополнительного среза и преобразования байтов в руны: временная сложность O(n), где n — количество байтов в строке. Поэтому если нужно выполнить итерацию по всем рунам, то используйте первое решение.
Если мы хотим получить доступ к i-й руне строки с помощью первого варианта, важно понимать, что доступа к индексу рун не будет, скорее мы будем знать только начальный индекс какой-то руны в последовательности байтов. В большинстве таких случаев предпочтительнее второй вариант:
s := "hêllo"
r := []rune(s)[4]
fmt.Printf("%c\n", r) // o
Этот код выводит четвертую руну, сначала преобразуя строку в срез руны.
Возможная оптимизация доступа к определенной руне
Если строка состоит из однобайтовых рун, то возможен один метод оптимизации: например, когда строка содержит буквы от A до Z и от a до z. Мы можем получить доступ к i-й руне без преобразования всей строки в срез рун, обратившись к байту напрямую с помощью s[i]:
s := "hello"
fmt.Printf("%c\n", rune(s[4])) // o
Если требуется выполнить итерацию по рунам строки, можно использовать цикл range напрямую по этой строке. Но следует помнить, что индекс соответствует не индексу руны, а начальному индексу последовательности байтов руны. Если мы хотим получить доступ к самой руне, нужно использовать значение элемента оператора range, а не индекс в строке, потому что руна может состоять из нескольких байтов. А если нужно получить i-ю руну строки, то в большинстве случаев следует преобразовывать строку в срез рун.
Далее рассмотрим часто встречающийся источник путаницы при использовании функций обрезки в пакете strings.
5.3. ОШИБКА #38: НЕПРАВИЛЬНО ИСПОЛЬЗОВАТЬ ФУНКЦИИ ОБРЕЗКИ
Одна из распространенных ошибок при использовании пакета strings — некоторая неразбериха, связанная с использованием TrimRight и TrimSuffix. Обе функции служат одной цели, и их довольно легко спутать.
В следующем примере мы используем TrimRight. Что выведет этот код?
fmt.Println(strings.TrimRight("123oxo", "xo"))
Ответ: 123. Но этого ли вы ожидали? Если нет, то, вероятно, вы ожидали результата функции TrimSuffix. Рассмотрим их обе.
TrimRight удаляет все завершающие руны, содержащиеся в заданном множестве. В нашем примере мы передали множество xo, которое содержит две руны: x и o. На рис. 5.2 показана логика этого действия.

TrimRight перебирает каждую руну в обратном порядке. Если руна является частью предоставленного множества, то функция удаляет ее, если нет, то останавливает итерации и возвращает оставшуюся строку. Вот почему наш пример возвращает 123.
С другой стороны, TrimSuffix возвращает строку без указанного завершающего суффикса:
fmt.Println(strings.TrimSuffix("123oxo", "xo"))
Поскольку 123oxo заканчивается на xo, этот код выводит 123o. Кроме того, удаление завершающего суффикса не является повторяющейся операцией, поэтому TrimSuffix(«123xoxo», «xo») возвращает 123xo.
Принцип будет тем же для левой части строки с TrimLeft и TrimPrefix:
fmt.Println(strings.TrimLeft("oxo123", "ox")) // 123
fmt.Println(strings.TrimPrefix("oxo123", "ox")) /// o123
strings.TrimLeft удаляет все начальные руны, содержащиеся в множестве, и, следовательно, выводит 123. TrimPrefix удаляет заданный начальный префикс, выводя o123.
Последнее замечание по теме: Trim применяет к строке как TrimLeft, так и TrimRight. Поэтому он удаляет все ведущие и последующие руны, содержащиеся в множестве:
fmt.Println(strings.Trim("oxo123oxo", "ox")) // 123
Таким образом, мы должны убедиться, что понимаем разницу между TrimRight/TrimLeft и TrimSuffix/TrimPrefix:
- TrimRight/TrimLeft удаляет замыкающие/ведущие руны в наборе.
- TrimSuffix/TrimPrefix удаляет указанный суффикс/префикс.
В следующем разделе углубимся в рассмотрение конкатенации строк.
5.4. ОШИБКА #39: НЕДОСТАТОЧНАЯ СТЕПЕНЬ ОПТИМИЗАЦИИ ПРИ КОНКАТЕНАЦИИ СТРОК
Для конкатенации строк в Go предусмотрены два основных подхода, но один из них в некоторых условиях может быть очень неэффективным. Разберемся, какой вариант следует предпочесть и когда.
Напишем код с функцией concat, которая объединяет все строковые элементы среза с помощью оператора +=:
func concat(values []string) string {
s := ""
for _, value := range values {
s += value
}
return s
}
Во время каждой итерации оператор += объединяет s со строкой value. На первый взгляд эта функция может показаться правильной. Но в этой реализации мы забываем одну из основных характеристик строки: ее неизменность. Следовательно, с каждой итерацией s не обновляется, вместо этого в памяти создается новая строка, что сильно влияет на время выполнения этой функции.
К счастью, у этой проблемы есть решение — пакет strings и структура Builder:

Здесь мы сначала создали структуру strings.Builder, задав ей нулевое значение. Во время каждой итерации мы создавали результирующую строку, вызывая метод WriteString, который добавляет содержимое value во внутренний буфер, сводя к минимуму копирование памяти.
Обратите внимание, что WriteString в качестве второго вывода возвращает ошибку, но мы намеренно ее игнорируем. Действительно, этот метод никогда не вернет ненулевую ошибку. Так для чего же он возвращает ошибку как часть своей сигнатуры? strings.Builder реализует интерфейс io.StringWriter, который содержит единственный метод: Write-String(s string) (n int, err error). Следовательно, чтобы соответствовать этому интерфейсу, WriteString должен возвращать ошибку.
ПРИМЕЧАНИЕ
Идиоматическое игнорирование ошибок мы обсудим в ошибке # 53 (не выполнять обработку ошибки).
Используя strings.Builder, мы также можем добавить:
- срез байта с помощью Write;
- одиночный байт с помощью WriteByte;
- одиночную руну с помощью WriteRune.
strings.Builder содержит внутри себя байтовый срез. Каждый вызов WriteString приводит к вызову append, применяемому к этому срезу. Это приводит к двум последствиям. Во-первых, эту структуру не следует использовать в режиме конкурентного выполнения, так как вызовы append приведут к состоянию гонки. Во-вторых, будет иметь место то, что мы уже видели при разборе ошибки #21 (неэффективная инициализация среза): если будущая длина среза уже известна, нужно заранее выделить под него место в памяти. Для этой цели в strings.Builder есть метод Grow(n int), он помогает гарантировать наличие места для еще n байт.
Взглянем на другую версию метода concat, вызвав Grow с общим количеством байтов:

Перед началом итераций мы вычисляем общее количество байтов, которое будет содержать окончательная строка, и присваиваем это значение переменной total. Обратите внимание, что нас интересует не количество рун, а количество байтов, поэтому мы используем функцию len. Затем мы вызываем Grow, чтобы гарантировать наличие места для байтов total, прежде чем проводить итерации по строкам.
Запустим бенчмарк для сравнения трех версий (v1 с использованием +=, v2 с использованием strings.Builder{} без предварительного резервирования места в памяти и v3 с использованием strings.Builder{} с предварительным резервированием). Входной срез содержит 1000 строк, и каждая строка содержит 1000 байт:
BenchmarkConcatV1-4 16 72291485 ns/op
BenchmarkConcatV2-4 1188 878962 ns/op
BenchmarkConcatV3-4 5922 190340 ns/op
Как мы видим, последний способ самый эффективный: на 99 % быстрее, чем v1, и на 78 % быстрее, чем v2. Мы можем спросить себя, как двукратное итерирование по входному срезу может ускорить код? Ответ кроется в ошибке # 21 (неэффективная инициализация среза): если для среза с заданной длиной или емкостью не выделено место заранее, то этот срез будет продолжать расти каждый раз, когда окажется заполненным, что приведет к дополнительным выделениям памяти и копиям. Следовательно, двукратное итерирование в этом случае — наиболее эффективный вариант.
strings.Builder — рекомендуемое решение для конкатенации списка строк. Обычно это решение следует использовать в циклах. Если просто нужно объединить несколько строк (например, имя и фамилию), использование strings.Builder не рекомендуется, так как это сделает код менее читаемым, чем использование оператора += или fmt.Sprintf.
С точки зрения производительности решение с использованием strings.Builder будет быстрее с того момента, когда нужно будет объединять более пяти строк. Несмотря на то что точное число зависит от многих факторов (например, от размера объединенных строк и от конкретного процессора), это может быть эмпирическим правилом, которое поможет понять, когда предпочесть одно решение другому. Также не стоит забывать, что если количество байтов будущей строки заранее известно, то следует использовать метод Grow для предварительного выделения места под внутренний байтовый срез.
Комментарии: 0
Пока нет комментариев