При работе любого корпоративного приложения образуются данные: файлы журналов, показатели, информация об активности пользователей, исходящие сообщения и другие. Правильное управление этими данными не менее важно, чем сами данные. Если вы архитектор, разработчик или инженер-технолог, но вы пока не знакомы с Apache Kafka, то из этой обновленной книги вы узнаете, как работать с потоковой платформой Kafka, позволяющей обрабатывать потоки данных в реальном времени. Дополнительные главы посвящены API AdminClient от Kafka, транзакциям, новым функциям безопасности и изменениям в инструментарии.Инженеры из Confluent и LinkedIn, ответственные за разработку Kafka, объясняют, как с помощью этой платформы развертывать производственные кластеры Kafka, писать надежные управляемые событиями микросервисы и создавать масштабируемые приложения для потоковой обработки данных. На подробных примерах вы изучите принципы проектирования Kafka, гарантии надежности, ключевые API и детали архитектуры.
Шапира Гвен
Гвен Шапира — главный инженер в компании Confluent, руководит командой облачно-ориентированного Kafka, которая отвечает за производительность, адаптируемость и многопользовательскую доступность Kafka.
Палино Тодд
Тодд Палино — главный штатный инженер по надежности сайта в LinkedIn, отвечает за планирование пропускной способности и эффективности всей платформы.
Сиварам Раджини
Раджини Сиварам — главный инженер в Confluent, проектирует и разрабатывает функции межкластерной репликации для Kafka.
Петти Крит
Крит Петти — технический руководитель по обеспечению надежности сайта Kafka в LinkedIn.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
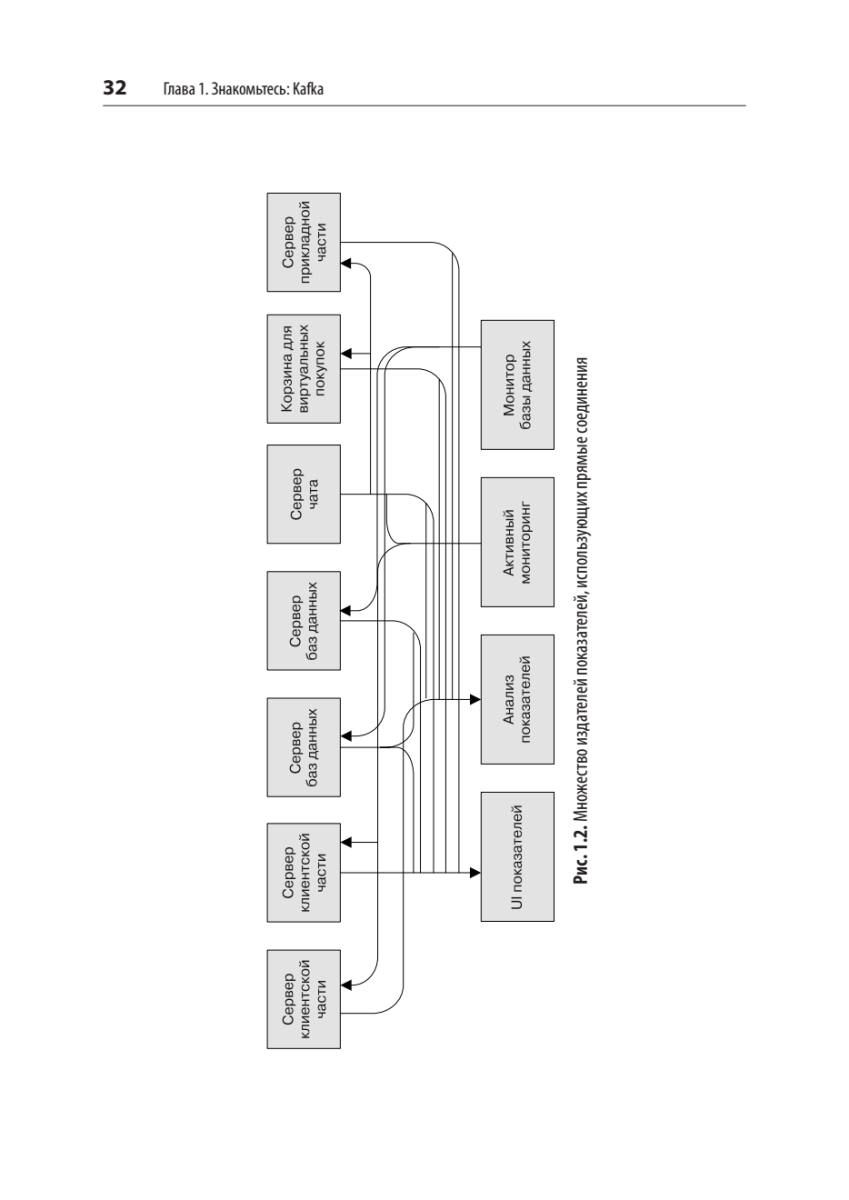{kind=link}
{kind=link}
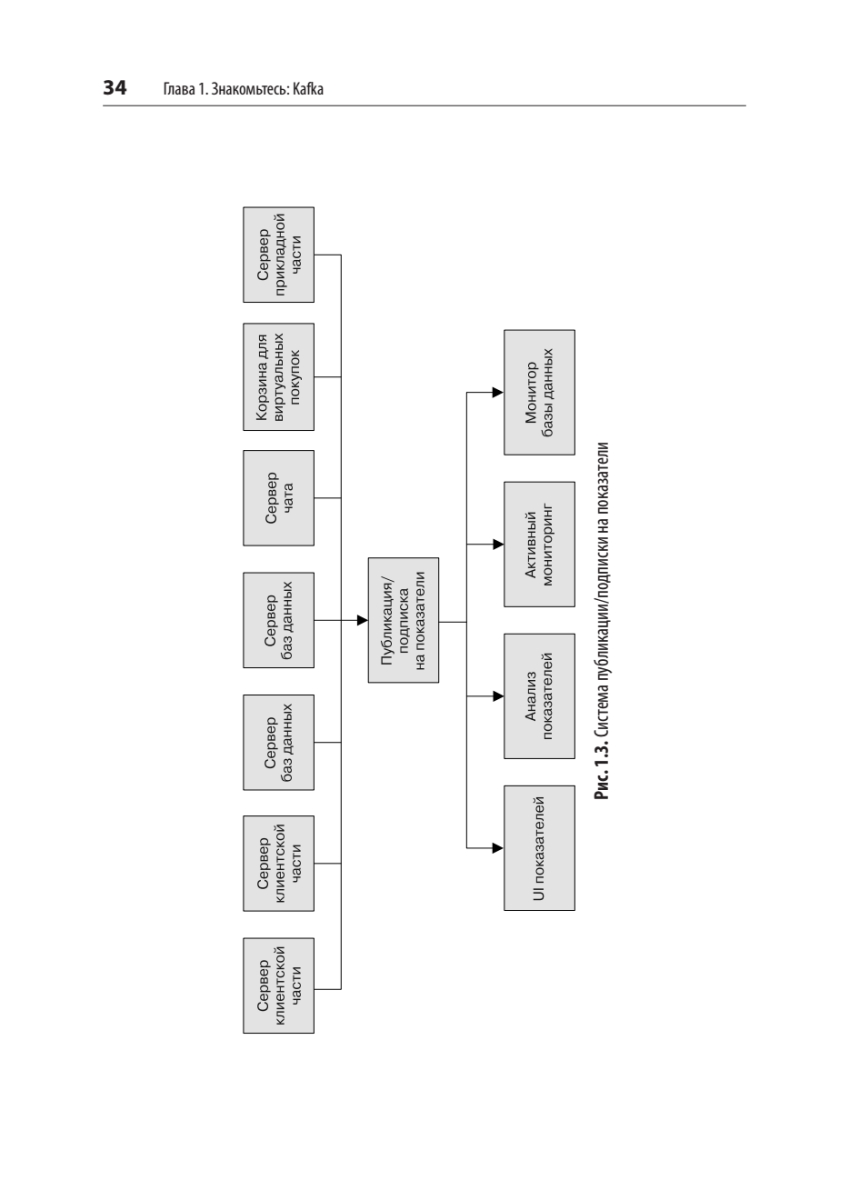{kind=link}
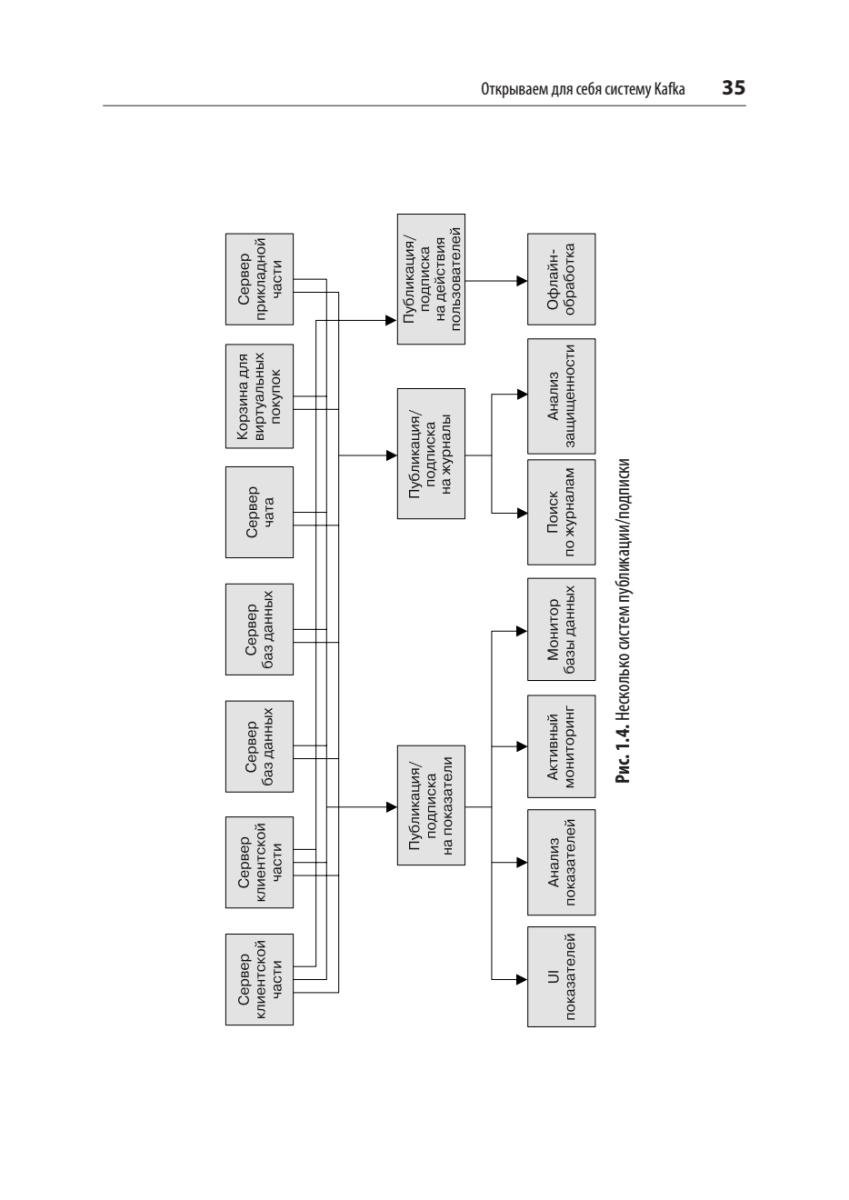{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
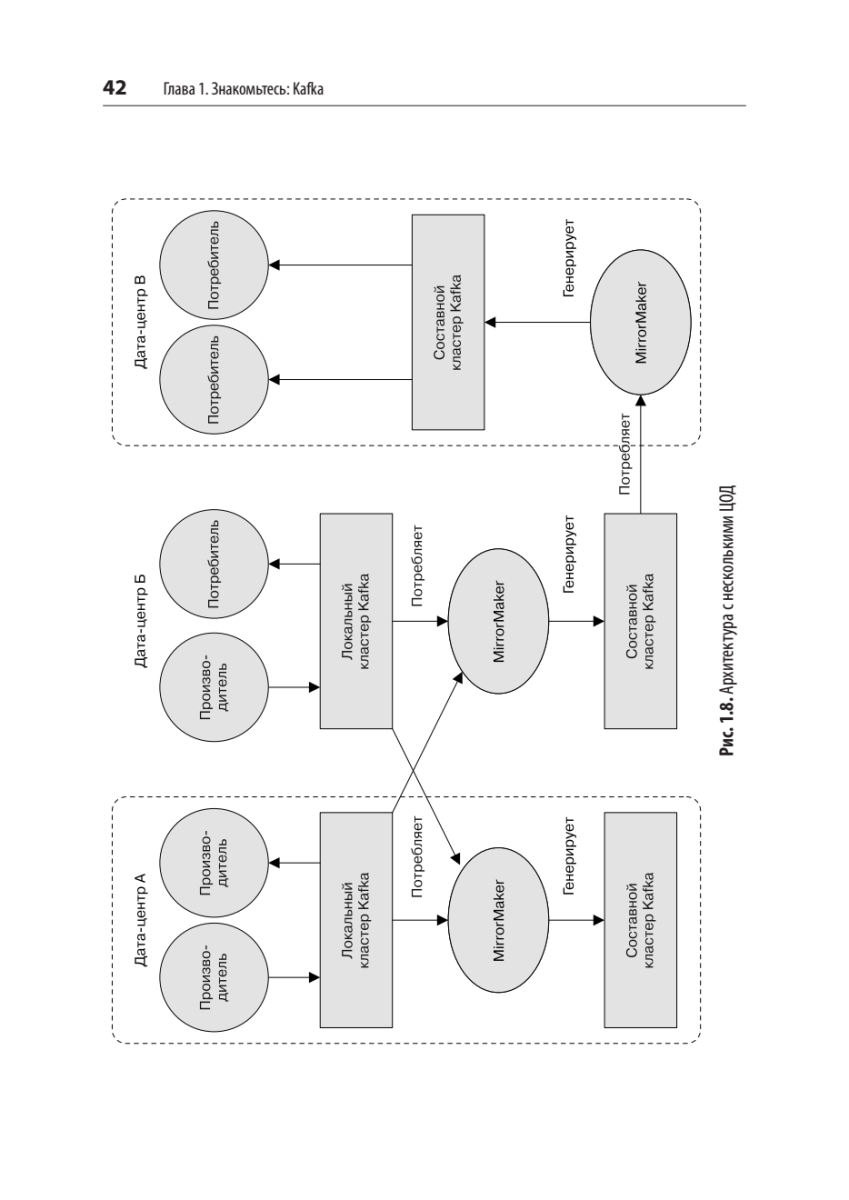{kind=link}