


Новости

01.03.2021
Книга «Стильный Java. Код, который работает всегда и везде»
Эта книга написана для разработчиков, которые хотят создавать качественный софт. Затронуты все ключевые показатели ПО: скорость, затраты памяти, надежность, удобочитаемость, потоковая безопасность, универсальность и элегантность. Реальные задачи и прикладные примеры кода на Java помогут надежно усвоить концепции. Пройдя все этапы создания центрального проекта книги, вы сможете уверенно выбрать правильный путь оптимизации собственного приложения.
4.4. Черная дыра [Memory4]
Последняя реализация в этой главе — Memory4 — ухитряется использовать всего 4 байта для каждого дополнительного резервуара за счет более высокой временной сложности. Идея этой реализации состоит в использовании одного статического массива с одной ячейкой на каждый резервуар, выполняющей сразу две функции. Для некоторых индексов массив содержит индекс следующего резервуара той же группы, как если бы группы хранились в связанных списках. Для резервуаров, у которых нет следующего резервуара (они изолированы или завершают свой список), в массиве хранится объем воды этого резервуара (и каждого резервуара той же группы).
Я предлагаю хранить и индексы, и объемы воды в одном массиве. Первые — целые числа, вторые — вещественные. Какой тип должен иметь массив? В голову приходят два варианта, приводящие к одинаковым затратам памяти (4 байта на резервуар):
1. Массив типа int, в котором содержимое ячейки должно интерпретироваться как объем воды и его можно делить на постоянную величину (фактически реализация чисел с фиксированной точкой). Например, если все объемы будут делиться на 10 000, они будут определяться с 5 цифрами в дробной части.
2. Массив типа float, в котором, чтобы содержимое ячейки интерпретировалось как индекс, необходимо убедиться, что значение является неотрицательным целым числом. В конце концов, неотрицательные целые числа (до некоторого значения) являются частным случаем чисел с плавающей точкой.
В листинге 4.12 я выбрал второй вариант, который выглядит проще, хотя, как вы вскоре увидите, у него есть свои недостатки.
Листинг 4.12. Memory4: поле — конструктор не нужен

Как при чтении содержимого ячейки отличать следующие значения от объемов воды? Можно воспользоваться доисторическим трюком и закодировать один из двух случаев положительными числами, а другой — отрицательными. Положительное число можно будет интерпретировать как индекс следующего резервуара, а отрицательное число будет обозначать объем воды в этом резервуаре с обратным знаком. Например, если nextOrAmount[4] == -2.5, это означает, что резервуар 4 является последним в своей группе (или изолированным) и содержит 2,5 единицы воды.
Есть небольшая проблема: в формате с плавающей точкой «положительный нуль» не отличается от «отрицательного». Эту неоднозначность можно устранить, считая, что нуль всегда обозначает объем, и никогда не использовать его в качестве индекса следующего резервуара. Чтобы не терять нулевую ячейку, увеличьте все индексы, хранящиеся в массиве, на 1 (смещение). Например, если за резервуаром 4 следует резервуар 7, nextOrAmount[4] == 8.
На рис. 4.8 представлено распределение памяти этой реализации после выполнения первых трех частей основного сценария. Значение 2,0 в первой ячейке — смещенный указатель на следующий резервуар — означает, что первый резервуар (a) связан с резервуаром под номером 1 (b). Значение –4,0 в третьей ячейке указывает, что c является последним резервуаром в своей группе, а каждый резервуар в этой группе содержит 4,0 единицы воды.
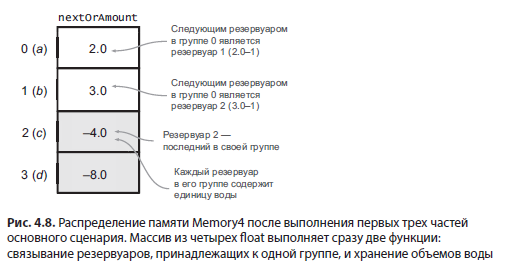
В листинге 4.13 представлен код метода getAmount. Он переходит к следующим значениям, как в связанном списке (вторая строка), пока не найдет последний резервуар в списке, который распознается по отрицательному или нулевому значению. Это значение представляет собой объем воды в резервуаре с обратным знаком. Обратите внимание на –1 в конце третьей строки кода (удаление смещения) и знак минус после return для возврата объема воды с правильным знаком.
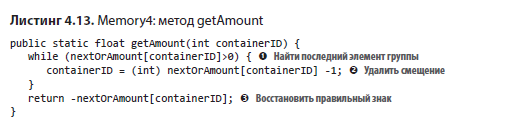
У float, использующегося для представления индексов массивов, есть еще один скрытый недостаток. Теоретически индексы массивов могут охватывать весь диапазон неотрицательных 32-разрядных целых чисел: от 0 до 2^31 ‒ 1 (приблизительно 2 млрд, также обозначается Integer.MAX_VALUE). Формат с плавающей точкой имеет существенно больший диапазон, но с изменяющимся разрешением. Расстояние между двумя соседними числами изменяется в зависимости от размера (рис. 4.9). Для малых значений (близких к нулю) следующее число с плавающей точкой расположено чрезвычайно близко. Для больших значений следующее число с плавающей точкой находится дальше. В какой-то момент расстояние превышает 1, и ряд чисел с плавающей точкой начинает пропускать целочисленные значения.
 Например, из-за расширенного диапазона тип float способен точно представить число 1E10 (10^10 или 10 млрд), чего не позволяет сделать целочисленный тип. Оба типа могут представить значение 1E8 (100 млн), но если переменная float содержит 1E8, то при увеличении на 1 она останется равной 1E8. У чисел с плавающей точкой не хватает значащих цифр для представления числа 100 000 001.
Например, из-за расширенного диапазона тип float способен точно представить число 1E10 (10^10 или 10 млрд), чего не позволяет сделать целочисленный тип. Оба типа могут представить значение 1E8 (100 млн), но если переменная float содержит 1E8, то при увеличении на 1 она останется равной 1E8. У чисел с плавающей точкой не хватает значащих цифр для представления числа 100 000 001.
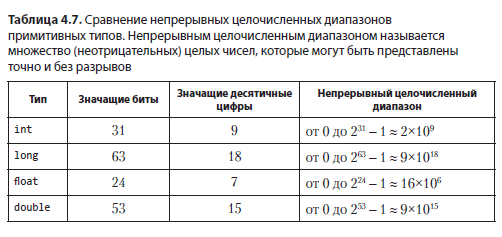
Расстояние между 1E8 и следующим числом типа float превышает 1. Хотя число 1E8 входит в диапазон чисел float, оно не входит в непрерывный целочисленный диапазон float, то есть в диапазон целых чисел, которые могут быть представлены точно и без разрывов. В табл. 4.7 приведены непрерывные целочисленные диапазоны для большинства числовых примитивных типов.
Неожиданный вопрос 5
Выберите тип данных и исходное значение переменной x таким образом, чтобы цикл
while (x+1==x) {} выполнялся бесконечно.
Использование float в качестве индекса массива — не лучшая идея. Оно сработает, только если индексы остаются в непрерывном целочисленном диапазоне, границы которого заметно меньше Integer.MAX_VALUE. Чтобы уточнить, насколько меньше, нужно учесть, что неотрицательные целые числа содержат 31 значащий бит, тогда как неотрицательные числа с плавающей точкой имеют только 24 значащих бита. Так как 31 – 24 = 7, порог для float в 2^7 = 128 раз меньше Integer.MAX_VALUE.
Если создать более 2^24 резервуаров, начнут происходить странные вещи и потребуется включить проверки времени выполнения в метод newContainer. Но эта глава посвящена потреблению памяти, поэтому будем придерживаться плана и оптимизировать только одно свойство кода за раз, а с факторами надежности подождем до главы 6. Остальной исходный код Memory4 можно найти в репозитории (https://bitbucket.org/mfaella/exercisesinstyle).
4.4.1. Временная сложность и затраты памяти
Один статический массив из Memory4 требует 4 байт для хранения ссылки на массив, 16 байт стандартных затрат массивов и 4 байт для каждой ячейки. В этой реализации заданное количество резервуаров всегда занимает одинаковый объем памяти, независимо от того, как они соединены. В табл. 4.8 приведены оценки затрат памяти для двух наших обычных сценариев.

За крайнюю экономию памяти приходится платить замедлением выполнения, как видно из табл. 4.9. Методы connect и addWater должны вычислять размер группы по заданному индексу произвольного резервуара группы. Для этого приходится возвращаться к первому резервуару группы, а затем обходить весь виртуальный список резервуаров для определения длины. Найти первый резервуар в группе не так просто, ведь это единственный элемент группы, на который не ссылается другой указатель. Чтобы найти его, необходимо обойти список в обратном порядке, что требует квадратичного времени.

С полным содержанием статьи можно ознакомиться на сайте "Хабрахабр":
https://habr.com/ru/company/piter/blog/541408/
Комментарии: 0
Пока нет комментариев