


Новости

13.07.2021
Книга «JavaScript для глубокого обучения: TensorFlow.js»
Умные веб-приложения захватили мир, а реализовать их в браузере или серверной части позволяет TensorFlow.js. Данная библиотека блестяще портируется, ее модели работают везде, где работает JavaScript. Специалисты из Google Brain создали книгу, которая поможет решать реальные прикладные задачи. Вы не будете скучать над теорией, а сразу освоите базу глубокого обучения и познакомитесь с продвинутыми концепциями ИИ на примерах анализа текста, обработки речи, распознавания образов и самообучающегося игрового искусственного интеллекта.
Работа с данными
Нынешней революцией машинного обучения мы во многом обязаны широкой доступности больших массивов данных. Без свободного доступа к большим объемам высококачественных данных такое взрывное развитие сферы машинного обучения было бы невозможно. Наборы данных сейчас доступны по всему Интернету, они свободно распространяются на таких сайтах, как Kaggle и OpenML, равно как и эталоны современных уровней производительности. Целые отрасли машинного обучения продвигаются вперед прежде всего за счет доступности «трудных» наборов данных, задавая планку и эталон для всего сообщества машинного обучения. Если считать, что развитие машинного обучения — «космическая гонка» нашего времени, то данные можно считать «ракетным топливом» благодаря их большому потенциалу, ценности, гибкости и критической важности для работы систем машинного обучения. Не говоря уже о том, что зашумленные данные, как и испорченное топливо, вполне могут привести к сбою системы. Вся эта глава посвящена данным. Мы рассмотрим рекомендуемые практики организации данных, обнаружения и исправления проблем в них, а также их эффективного использования.
«Но разве мы не работали с данными все это время?» — спросите вы. Да, в предыдущих главах мы работали с самыми разнообразными источниками данных. Мы обучали модели для изображений как на искусственных, так на и взятых с веб-камеры изображениях. Мы использовали перенос обучения для создания средства распознавания речи на основе набора аудиосемплов и брали данные из табличных наборов для предсказания цен. Что же здесь еще обсуждать? Разве мы не достигли мастерства в работе с данными?
Вспомните, какие паттерны использования данных встречались в предыдущих примерах. Обычно сначала нужно было скачать данные из удаленного источника. Далее мы (обычно) приводили их в нужный формат, например преобразовывали строки в унитарные векторы слов или нормализовали средние значения и дисперсии табличных источников данных. После этого мы организовывали данные в батчи и преобразовывали их в стандартные массивы чисел, представленные в виде тензоров, а затем уже подавали на вход модели. И это все еще до первого шага обучения.
Подобный паттерн скачивания — преобразования — организации по батчам очень распространен, и библиотека TensorFlow.js включает инструменты для его упрощения, модульной организации и снижения числа ошибок. В этой главе мы расскажем вам об инструментах из пространства имен tf.data и главном из них — tf.data.Dataset, позволяющем выполнять отложенную потоковую обработку данных. Благодаря этому подходу можно скачивать, преобразовывать данные и обращаться к ним по мере необходимости, вместо того чтобы скачивать источник данных полностью и хранить его в памяти для возможного доступа. Отложенная потоковая обработка существенно упрощает работу с источниками данных, не помещающимися в памяти отдельной вкладки браузера или даже в оперативной памяти машины.
Сначала мы познакомим вас с API tf.data.Dataset и покажем, как его настраивать и связывать с моделью. А затем приведем немного теории и расскажем об утилитах, предназначенных для просмотра и исследования данных с целью поиска и разрешения возможных проблем. Завершается глава рассказом о дополнении данных — методе расширения набора данных путем создания их искусственных псевдопримеров для повышения качества работы модели.
Работа с данными с помощью пространства имен tf.data
Как обучить спам-фильтр, если размер базы данных электронной почты занимает сотни гигабайт и база требует специальных учетных данных для доступа? Как создать классификатор изображений, если база данных обучающих изображений слишком велика и не помещается на одной машине?
Обращение к большим массивам данных и выполнение операций с ними — ключевой навык любого специалиста по машинному обучению, но до сих пор мы имели дело лишь с приложениями, в которых данные прекрасно помещались в доступной приложению оперативной памяти. Множество приложений требуют работы с большими, громоздкими и, возможно, содержащими персональную информацию источниками данных, для которых подобная методика не подходит. Большие приложения требуют технологии доступа к данным, размещенным в удаленном источнике, по частям, по мере требования.
TensorFlow.js включает интегрированную библиотеку, предназначенную как раз для подобных операций с данными. Эта библиотека, вдохновленная API tf.data Python-версии TensorFlow, создана, чтобы пользователи могли с помощью коротких и удобочитаемых команд вводить данные, выполнять их предварительную обработку и переправлять их далее. Вся эта функциональность доступна в пространстве имен tf.data, если предварительно импортировать TensorFlow.js с помощью оператора следующего вида:

Объект tf.data.Dataset
Основная работа с модулем tfjs-data выполняется через единственный объект tf.data.Dataset. Он предоставляет простой, высокопроизводительный, с широкими возможностями настройки способ обхода и обработки больших (потенциально вообще неограниченных) списков элементов данных. В самом первом приближении можно считать Dataset аналогом итерируемой коллекции произвольных элементов, в чем-то напоминающей Stream в Node.js. При запросе очередного элемента из Dataset внутренняя реализация скачивает его и обеспечивает доступ к нему либо при необходимости запускает функцию для его создания. Эта абстракция упрощает обучение модели на объемах данных, целиком не помещающихся в оперативной памяти, а также облегчает совместное использование и организацию объектов Dataset как полноправных объектов в тех случаях, когда их более одного. Dataset экономит память за счет потоковой передачи лишь требуемых битов данных, и не приходится обращаться ко всему массиву. API Dataset также оптимизирует работу, по сравнению с «наивной» реализацией, за счет упреждающей выборки значений, которые могут понадобиться.
Создание объекта tf.data.Dataset
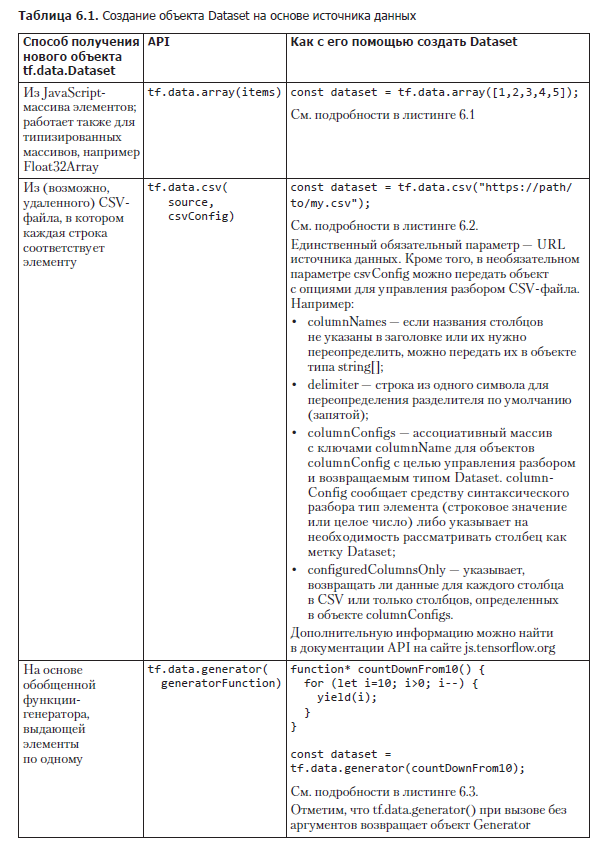
По состоянию на версию 1.2.7 TensorFlow.js существует три способа подключения объекта tf.data.Dataset к поставщику данных. Мы довольно подробно рассмотрим их все, а краткую сводку вы найдете в табл. 6.1.
Создание объекта tf.data.Dataset из массива
Простейший способ создать новый объект tf.data.Dataset — сформировать его на основе JavaScript-массива. Создать Dataset на основе загруженного в память массива можно с помощью функции tf.data.array(). Конечно, не будет никакого выигрыша в скорости обучения или экономии памяти, по сравнению с непосредственным использованием массива, но у доступа к массиву через объект Dataset есть свои преимущества. Например, использование объектов Dataset упрощает организацию предварительной обработки, а также обучение и оценку благодаря простым API model.fitDataset() и model.evaluateDataset(), как мы увидим в разделе 6.2. В отличие от model.fit(x, y) вызов model.fitDataset(myDataset) не перемещает сразу все данные в память GPU, благодаря чему можно работать с наборами данных, не помещающимися туда целиком. Ограничение по памяти движка V8 JavaScript (1,4 Гбайт в 64-битных системах) обычно превышает объем, который TensorFlow.js может целиком разместить в памяти WebGL. Кроме того, использование API tf.data — одна из рекомендуемых практик инженерии разработки ПО, ведь оно упрощает модульный переход на другие типы данных без особых изменений кода. Без абстракции объекта Dataset подробности реализации источника данных могут легко просочиться в код его использования при обучении модели — узел, который придется распутывать при переходе на другую реализацию.
Для создания объекта Dataset из уже существующего массива можно воспользоваться tf.data.array(itemsAsArray), как показано в листинге 6.1.
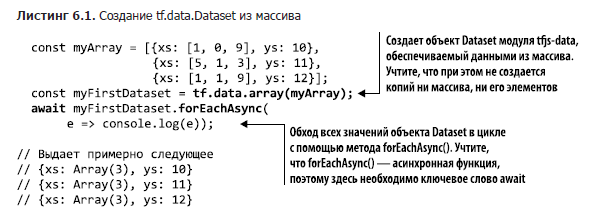
Мы проходим по всем элементам Dataset в цикле с помощью функции forEachAsync(), по очереди выдающей все элементы. Больше подробностей о функции forEachAsync() вы можете найти в подразделе 6.1.3.
Элементы объектов Dataset, помимо тензоров, могут содержать простые типы данных JavaScript1(например, числа и строковые значения), а также кортежи, массивы и многократно вложенные объекты подобных структур данных. В этом крошечном примере структура всех трех элементов объекта Dataset одинакова: это объекты с одинаковыми ключами и одним типом значений для ключей. В принципе, tf.data.Dataset позволяет комбинировать различные типы элементов, но наиболее распространен сценарий использования, при котором элементы Dataset представляют собой осмысленные семантические единицы одного типа. Обычно они отражают примеры одной сущности. Поэтому, за исключением очень необычных сценариев использования, типы данных и структуры всех элементов совпадают.
С полным содержанием статьи можно ознакомиться на сайте "Хабрахабр":
Комментарии: 0
Пока нет комментариев